1. Unterrichtsblock

Einführung in KI
- Künstliche Intelligenz (KI) ist eine Teilmenge der Informatik. Sie umfasst Computerprogramme, die eigenständig Probleme lösen können – also ohne dass ein Mensch jeden Schritt vorgibt.
Unterschied schwache KI und starke KI
Bei künstlichen Intelligenzen gilt es zwischen schwacher und starker KI zu unterscheiden. Während sich die schwache KI in der Regel mit konkreten Anwendungsproblemen beschäftigt, geht es bei der starken KI darum, eine allgemeine Intelligenz zu schaffen, die der des Menschen gleicht oder diese übertrifft.
Aufgabe 1.1 Starke vs. Schwache KI verstehen
Schau dir das Video „STARKE KI vs. SCHWACHE KI“ an.
Achte dabei besonders auf folgende Punkte:
- Was ist der Unterschied zwischen starker und schwacher KI?
- Welche Beispiele werden genannt?
- Warum ist starke KI bisher nur Theorie?
Deine Aufgabe:
Wähle eine der folgenden Möglichkeiten:
- Vergleich schreiben Erstelle eine kurze Gegenüberstellung: → Was kann schwache KI? → Was würde starke KI können? → Wo begegnet dir schwache KI im Alltag?
- Begriffe erklären Erkläre die Begriffe „starke KI“ und „schwache KI“ in eigenen Worten – so, dass jemand ohne Vorkenntnisse sie versteht.
- Diskussionsimpuls Schreibe eine kurze Meinung: → Glaubst du, dass starke KI in Zukunft möglich ist? → Was wären Chancen und Risiken?
Zusammenfassung:

Anwendungsbereiche
Hautkrebserkennung
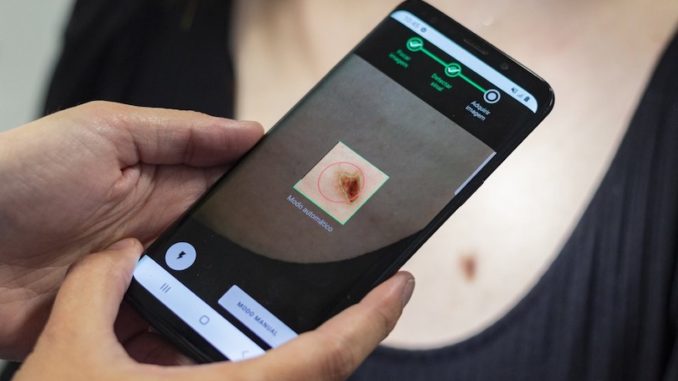
Autonome Waffensysteme

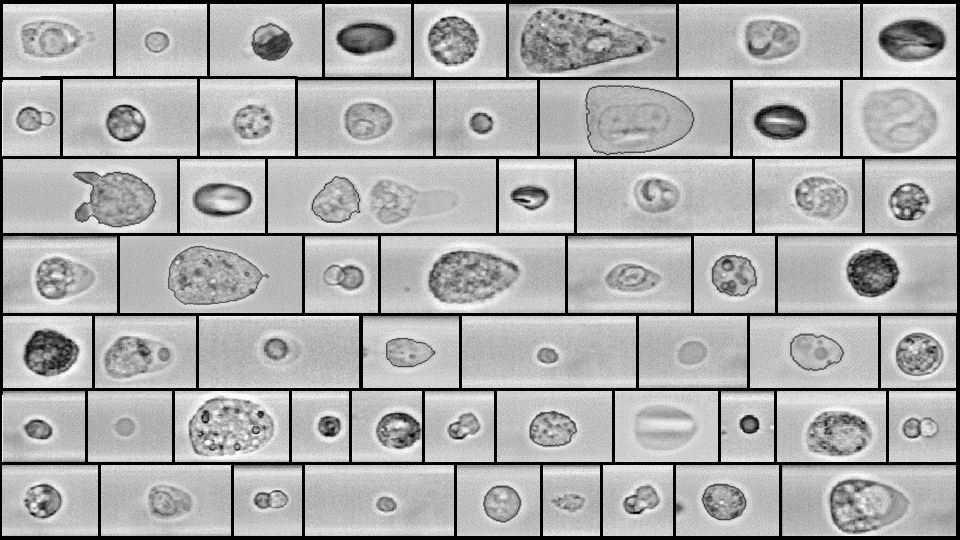
Blutuntersuchung und Erkennung von Erregern
Autonomes Fahren

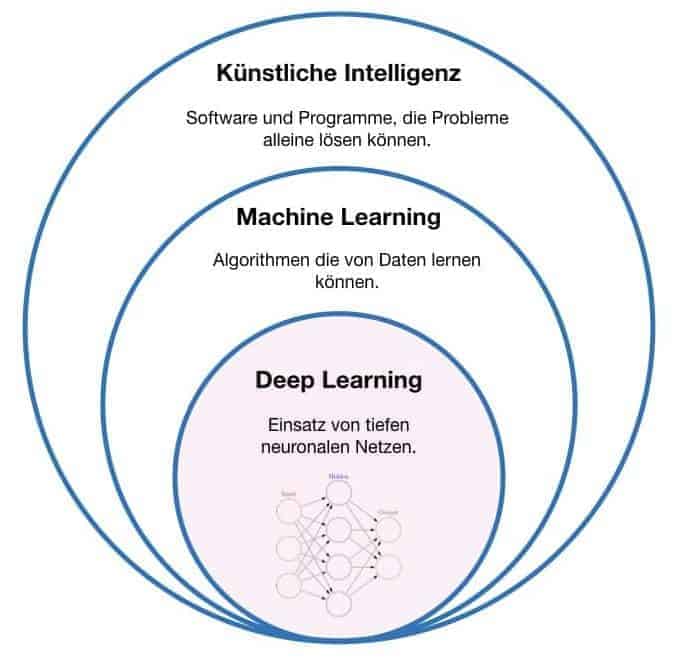
Grundlagen maschinelles Lernen & Deep Learning
Maschinelles Lernen
- Maschinelles Lernen (ML) ist eine Teilmenge der KI. Es wird eingesetzt, damit die KI aus Beispielen lernt und sich verbessert – also beim Problemlösen dazulernt.
Nachdem du nun weißt, was maschinelles Lernen grundsätzlich bedeutet, schauen wir uns an, wie ein KI-Modell zeitlich arbeitet: Es durchläuft eine Lernphase, in der es trainiert wird, und eine Anwendungsphase, in der es sein Wissen einsetzt.
1. Lernphase (Training)
In der Lernphase wird das KI-Modell trainiert, also mit vielen Beispielen „gefüttert“. Das Ziel: Die KI soll Muster erkennen und daraus Regeln ableiten, um später neue Daten richtig zu beurteilen.
Merkmale:
- Die Daten sind meist gelabelt (z. B. „Katze“ oder „Hund“)
- Das Modell passt seine internen Parameter (z. B. Gewichte in einem neuronalen Netz) so an, dass es möglichst wenig Fehler macht
- Diese Phase braucht oft viel Rechenleistung und Zeit
Beispiel: Eine KI soll lernen, Fake News zu erkennen. → Sie bekommt tausende Artikel mit dem Label „vertrauenswürdig“ oder „Fake News“ → Sie lernt, welche sprachlichen Merkmale typisch sind
2. Anwendungsphase (Inference)
In der Anwendungsphase wird das fertig trainierte Modell eingesetzt, um neue, unbekannte Daten zu bewerten oder Entscheidungen zu treffen.
Merkmale:
- Die KI nutzt ihr gelerntes Wissen, um Vorhersagen zu machen
- Es werden keine Labels mehr benötigt
- Die Rechenlast ist meist geringer als beim Training
Beispiel: Die Fake-News-KI bekommt einen neuen Artikel, den sie noch nie gesehen hat. → Sie bewertet ihn als „wahrscheinlich glaubwürdig“ oder „verdächtig“ – basierend auf dem, was sie gelernt hat
Didaktischer Vergleich:
Die Lernphase ist wie das Üben für eine Prüfung – viele Beispiele, viel Wiederholung. Die Anwendungsphase ist wie das Schreiben der Prüfung – die KI muss zeigen, was sie gelernt hat.
Deep Learning
- Deep Learning (DL) ist eine spezielle Methode im maschinellen Lernen. Dabei nutzt die KI sogenannte „tiefe neuronale Netze“, um besonders komplexe Aufgaben zu bewältigen – z. B. Bilder erkennen oder Sprache verstehen.
Aufgabe 1.1 – Neuronale Netze verstehen
Du hast gerade gelernt, wie künstliche Intelligenz, maschinelles Lernen und Deep Learning zusammenhängen. Jetzt geht es darum, wie neuronale Netze funktionieren – also wie eine KI aus Daten lernt.
Schau dir das Video Neuronale Netze – Basiswissen an. Achte dabei besonders auf folgende Punkte:
- Was ist ein künstliches Neuron?
- Wie funktioniert ein neuronales Netz?
- Was passiert beim Training?
- Welche Begriffe tauchen immer wieder auf?
Deine Aufgabe:
Wähle eine der folgenden Möglichkeiten:
- Kernaussagen zusammenfassen Schreibe in eigenen Worten auf, was du aus dem Video gelernt hast. Ca. 5–7 Stichpunkte reichen.
- Mindmap erstellen Zeichne eine Mindmap mit dem Begriff „Neuronale Netze“ in der Mitte. → Verzweigungen könnten sein: Aufbau, Training, Anwendung, wichtige Begriffe
- Begriffe erklären Wähle 3 Begriffe aus dem Video (z. B. „Gewicht“, „Schwellwert“, „Training“) und erkläre sie so, dass jemand ohne Vorkenntnisse sie versteht.
Du kannst die Aufgabe allein oder in Partnerarbeit machen. Ziel ist, dass du die Grundidee von neuronalen Netzen verstehst – denn darauf bauen viele KI-Modelle später auf.
Was ist ein KI-Modell?
In der letzten Einheit hast du gelernt, dass Deep Learning ein Teilbereich der künstlichen Intelligenz ist – und dass dabei sogenannte neuronale Netze zum Einsatz kommen. Jetzt geht es darum, was ein KI-Modell eigentlich ist und wie es entsteht.
Ein KI-Modell ist ein trainiertes neuronales Netz, das gelernt hat, bestimmte Aufgaben zu lösen – zum Beispiel Bilder erkennen, Texte schreiben oder Sprache verstehen. Es hilft dem Computer, neue Daten zu bewerten, zu entscheiden oder vorherzusagen. Damit das klappt, muss das Modell vorher „trainiert“ werden – also viele Beispiele sehen und daraus lernen.
Dabei ist wichtig zu unterscheiden: Die Modellarchitektur wird vorher festgelegt, je nachdem, welche Aufgabe die KI lösen soll. 👉 Das Modell selbst entsteht erst durch das Training: Es passt seine Einstellungen (z. B. Gewichte und Schwellenwerte) so an, dass es aus Beispielen lernt und später neue Daten richtig einschätzen kann.
Man kann sich das vorstellen wie ein leeres Gehirn, das erst durch Erfahrung „klug“ wird. Die Architektur ist der Bauplan – das trainierte Modell ist das fertige Werkzeug.
Alltagsvergleich: Burger-Erkennung
Stell dir vor, du arbeitest bei einem Lieferservice. Du bekommst viele Bilder von Gerichten – und zu jedem Bild steht dabei, ob es sich um einen Burger handelt oder nicht.
Beispiel:🍔 Burger mit Käse → ja 🌯 Wrap mit Salat → nein 🍔 Burger mit Bacon → ja 🥪 Sandwich → nein
Nach einer Weile erkennst du: Ein Burger hat meistens ein Brötchen oben und unten, Fleisch in der Mitte und sieht „gestapelt“ aus. Jetzt bekommst du ein neues Bild – du schaust drauf und sagst: „Ja, das ist ein Burger!“ → So funktioniert ein KI-Modell: Es sieht viele Beispiele, lernt daraus und kann neue Dinge einschätzen.
Aufgabe 1.2 Erfinde dein eigenes KI-Modell
Du hast gelernt, wie ein KI-Modell aus Beispielen lernt – z. B. ob ein Gericht ein Burger ist oder nicht. Jetzt bist du dran: Überlege dir ein eigenes Beispiel, bei dem eine KI etwas erkennen oder entscheiden soll.
Nutze die folgenden Fragen zur Hilfe:
- Was soll die KI lernen? (z. B. „Ist das TikTok-Video lustig?“)
- Welche Beispiele könnte man der KI zeigen? (z. B. Videos, Bilder, Texte – immer mit der richtigen Antwort dabei)
- Wie würde die KI später entscheiden? (z. B. „Wenn viele Leute lachen und der Ton witzig ist, dann ist das Video wahrscheinlich lustig“)
Beispiel: „Meine KI soll erkennen, ob ein TikTok-Video lustig ist oder nicht. Ich zeige ihr 100 Videos – bei jedem steht dabei: lustig oder nicht lustig. Nach dem Training kann sie neue Videos einschätzen.“
Woher weiß die KI, ob gelacht wurde? Damit die KI lernen kann, ob ein Video lustig ist, braucht sie Hinweise – zum Beispiel: Tonanalyse: Gibt es hörbares Lachen im Video? Kommentare: Schreiben Leute „Ich hab mich totgelacht“ oder benutzen Emojis wie 🤣? Likes & Shares: Lustige Videos werden oft geliked und geteilt. Manuelle Bewertung: Menschen geben beim Training die Info: „Dieses Video ist lustig“. Wichtig ist: Die KI braucht viele Beispiele mit Lösung, damit sie später neue Dinge erkennen kann – genau wie du beim Lernen.
Modelltypen & Architektur
In der letzten Einheit hast du gelernt, was ein KI-Modell ist und wie es durch Training entsteht. Jetzt schauen wir uns an, welche Arten von Modellen es gibt – und wie sie aufgebaut sind. Denn nicht jede KI funktioniert gleich: Je nach Aufgabe braucht man eine andere Struktur – das nennt man Modellarchitektur.
Übersicht: Wichtige Modelltypen in der KI
- Künstliche neuronale Netze (ANN) Einfache Netzwerke mit Eingabe-, versteckten und Ausgabeschichten. → Einsatz: Grundlagen, einfache Klassifikationen
- Tiefe neuronale Netze (DNN) Erweiterte ANN mit mehreren Schichten, die komplexe Muster erkennen können. → Einsatz: Sprache, Bilder, Texte
- Convolutional Neural Networks (CNN) Spezialisierte Netze für Bilddaten – erkennen Kanten, Farben, Formen. → Einsatz: Bilderkennung, z. B. Hautanalyse oder Verkehrszeichen
- Recurrent Neural Networks (RNN) Netzwerke mit „Gedächtnis“, die sich vorherige Informationen merken. → Einsatz: Texte, Sprache, Zeitreihen (z. B. Wetterdaten)
- Transformer-Modelle Verarbeiten alle Eingaben gleichzeitig und achten auf Zusammenhänge. → Einsatz: Übersetzungen, Textverständnis, Chatbots
- LLM (Large Language Models) Sehr große Transformer-Modelle mit Milliarden Parametern. → Einsatz: Textgenerierung, Zusammenfassungen, KI-gestützte Dialogsysteme wie ChatGPT
Die besten offenen LLMs: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard
Was ist der Unterschied zwischen Modelltyp und Architektur?
| Begriff | Bedeutung | Beispiel |
|---|---|---|
| Modelltyp | Die Art des Modells – also wofür es gedacht ist | z. B. CNN für Bilder, RNN für Texte |
| Modellarchitektur | Der genaue Aufbau – also wie viele Schichten, welche Funktionen, wie die Daten fließen | z. B. ein CNN mit 3 Convolution-Schichten und MaxPooling |
Ein Modelltyp beschreibt die grundsätzliche Kategorie eines KI-Modells – also ob es sich zum Beispiel um ein Bildmodell (wie ein CNN), ein Textmodell (wie ein RNN oder Transformer) oder ein Sprachmodell handelt. Die Modellarchitektur hingegen legt fest, wie dieses Modell im Detail aufgebaut ist: wie viele Schichten es hat, wie die Daten verarbeitet werden und welche Funktionen verwendet werden. Man kann sich das vorstellen wie bei einem Auto: Der Modelltyp ist die Entscheidung für ein Fahrzeug – etwa ein Elektroauto, ein SUV oder ein Kleinwagen. Die Architektur ist dann der konkrete Bauplan dieses Fahrzeugs – also ob es zwei oder vier Türen hat, welche Motorleistung verbaut ist und ob ein Navigationssystem integriert ist.
Aufgabe 1.3 Modell-Matching: Welcher Typ passt zu welcher Aufgabe?
Aufgabenstellung: Du bekommst verschiedene KI-Anwendungsfälle. Entscheide, welcher Modelltyp (z. B. CNN, RNN, Transformer) am besten passt – und begründe deine Wahl.
- Eine KI soll erkennen, ob ein Foto ein Hund oder eine Katze zeigt.
- Eine KI soll vorhersagen, wie sich der Stromverbrauch über die nächsten Tage entwickelt.
- Eine KI soll automatisch E-Mails beantworten.
- Eine KI soll erkennen, ob ein gesprochener Satz traurig oder fröhlich klingt.
- Eine KI soll einen Text zusammenfassen.
Trainingsdaten & Lernformen
Was sind Trainingsdaten?
Ein KI-Modell lernt nicht von allein – es braucht Beispiele. Diese Beispiele nennt man Trainingsdaten. Sie zeigen dem Modell, wie eine Aufgabe gelöst wird. → Beispiel: Wenn eine KI lernen soll, ob ein Artikel glaubwürdig ist, bekommt sie viele Texte mit dem Hinweis „vertrauenswürdig“ oder „Fake News“. Die KI erkennt Muster in diesen Daten und passt ihre Einstellungen so an, dass sie später neue Inhalte richtig einschätzen kann.
Warum sind Trainingsdaten so wichtig?
- Gute Daten = gutes Modell Wenn die Daten klar, vielfältig und korrekt sind, kann die KI gut lernen.
- Schlechte Daten = schlechte Entscheidungen Wenn die Daten einseitig oder fehlerhaft sind, lernt die KI falsch. → Beispiel: Wenn eine Fake-News-KI nur politische Artikel aus einer Richtung sieht, wird sie voreingenommen.
- Bias (Verzerrung) Einseitige Trainingsdaten führen zu Vorurteilen im Modell. → Das kann gefährlich werden – z. B. bei Nachrichten, Bewerbungen oder Strafverfolgung.
Technische Voraussetzungen für Trainingsdaten
1. Datenformat & Struktur
- Die Daten müssen in einem verarbeitbaren Format vorliegen – z. B. CSV, JSON, Bilddateien, Textdateien.
- Einheitliche Struktur ist wichtig: z. B. bei Tabellen gleiche Spalten, bei Bildern gleiche Auflösung.
- Bei gelabelten Daten: klare Zuordnung von Eingabe und Zielwert (z. B. „Bild → Katze“).
2. Datenmenge & Vielfalt
- Je nach Modelltyp braucht man große Mengen an Daten – z. B. Tausende Bilder für ein CNN.
- Die Daten sollten vielfältig und repräsentativ sein, damit das Modell nicht einseitig lernt.
3. Datenqualität
- Keine Duplikate, keine fehlerhaften Einträge, keine unvollständigen Daten.
- Bei Texten: Rechtschreibung, Formatierung, Sprache beachten.
- Bei Bildern: gute Auflösung, klare Inhalte, keine Verzerrungen.
4. Labeling (bei überwachtem Lernen)
- Die Daten müssen korrekt beschriftet sein – z. B. „Fake News“ vs. „vertrauenswürdig“.
- Labels sollten konsistent und nachvollziehbar sein.
- Oft braucht man Tools oder menschliche Annotator:innen für die Beschriftung.
5. Datensicherheit & Datenschutz
- Besonders bei personenbezogenen Daten: DSGVO beachten!
- Daten müssen anonymisiert oder pseudonymisiert sein.
- Zugriff und Speicherung müssen sicher geregelt sein.
6. Technische Infrastruktur
- Speicherplatz: große Datenmengen brauchen viel Speicher.
- Rechenleistung: für das Training braucht man oft GPUs oder Cloud-Ressourcen.
- Schnittstellen: Daten sollten über APIs oder Uploads ins Trainingssystem eingebunden werden können.
Maschinelles Lernen Grundarten
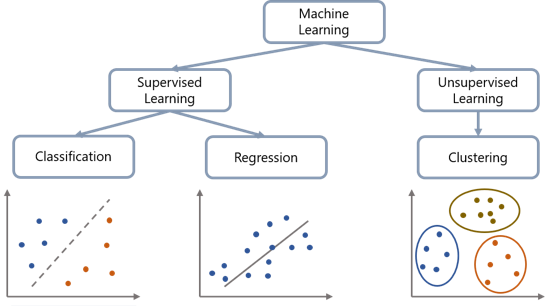
Lernformen beschreiben die Art und Weise, wie ein KI-Modell aus Daten lernt. Die Grafik zeigt die drei Grundformen des maschinellen Lernens: überwachtes, unüberwachtes und verstärkendes Lernen. Beim überwachten Lernen erhält die KI gelabelte Daten, etwa zur Klassifikation von Texten oder zur Prognose von Umsatz und Stromverbrauch. Unüberwachtes Lernen funktioniert ohne vorgegebene Antworten – die KI erkennt selbst Muster, etwa bei Kundensegmentierung oder Datenvisualisierung. Verstärkendes Lernen basiert auf Belohnung und Bestrafung, wie bei Spiel-KI oder autonomem Fahren. Die Darstellung macht deutlich, wie unterschiedlich KI-Modelle lernen und welche Aufgaben jeweils damit gelöst werden können.
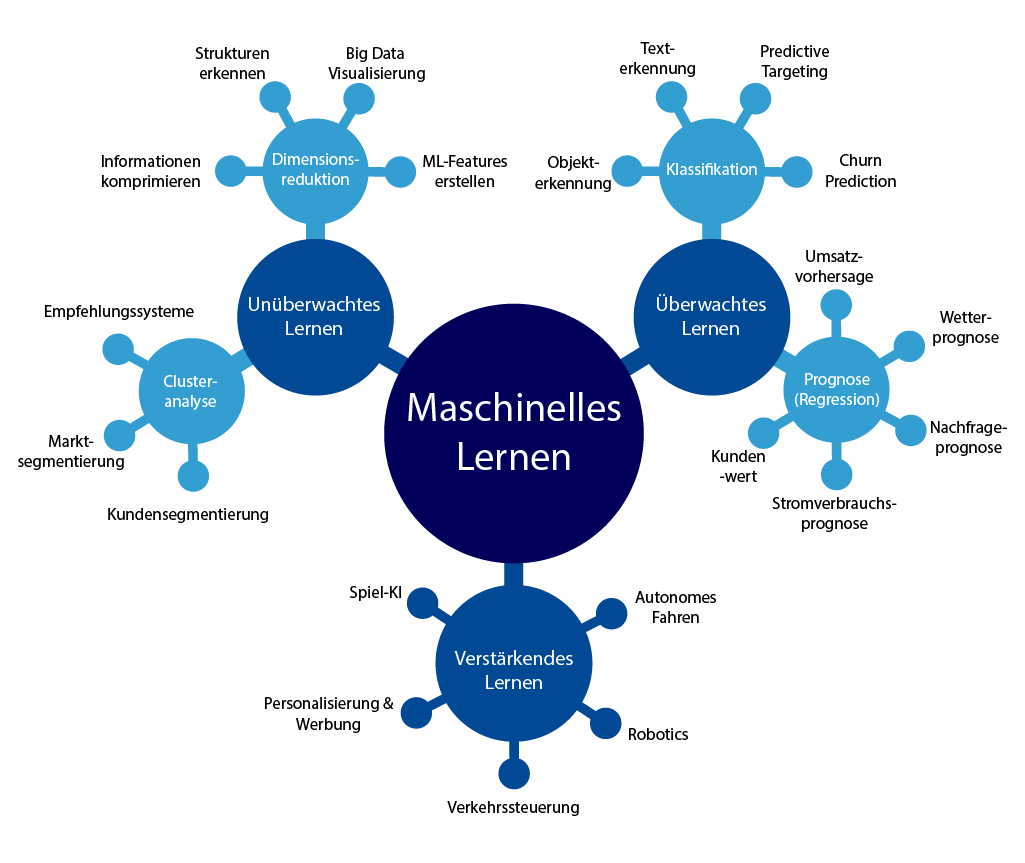
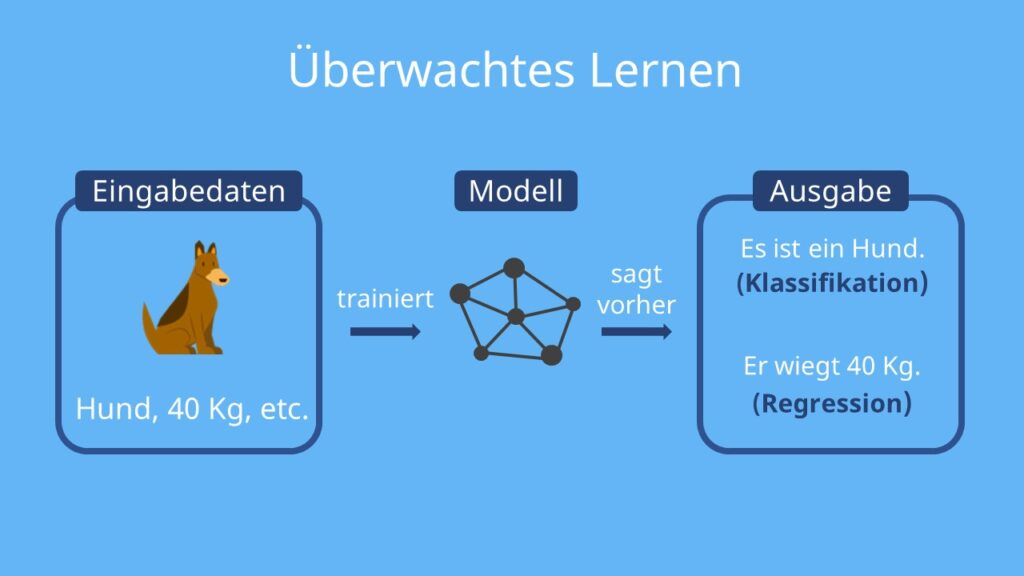
Überwachtes Lernen (supervised learning)
Zieldaten werden händisch bearbeitet
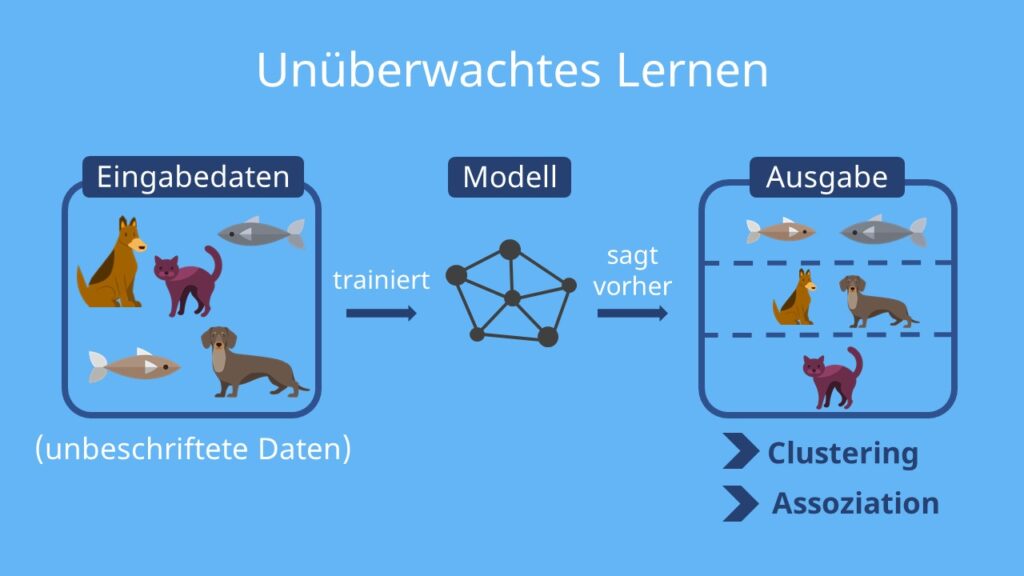
Unüberwachtes Lernen (unsupervised learning)
- Benötigt keine Zieldaten
- Für die Gruppierung geeignet (Clustering)
- Geeignet mit sehr großen Datenmengen
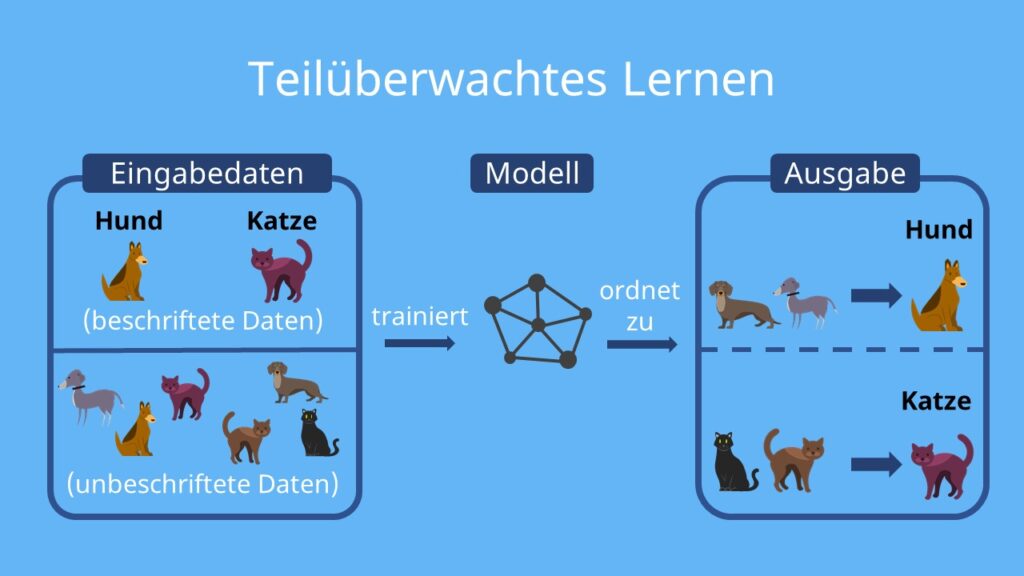
Teilüberwachtes Lernen
Mischform aus überwachtem und unüberwachtem Lernen
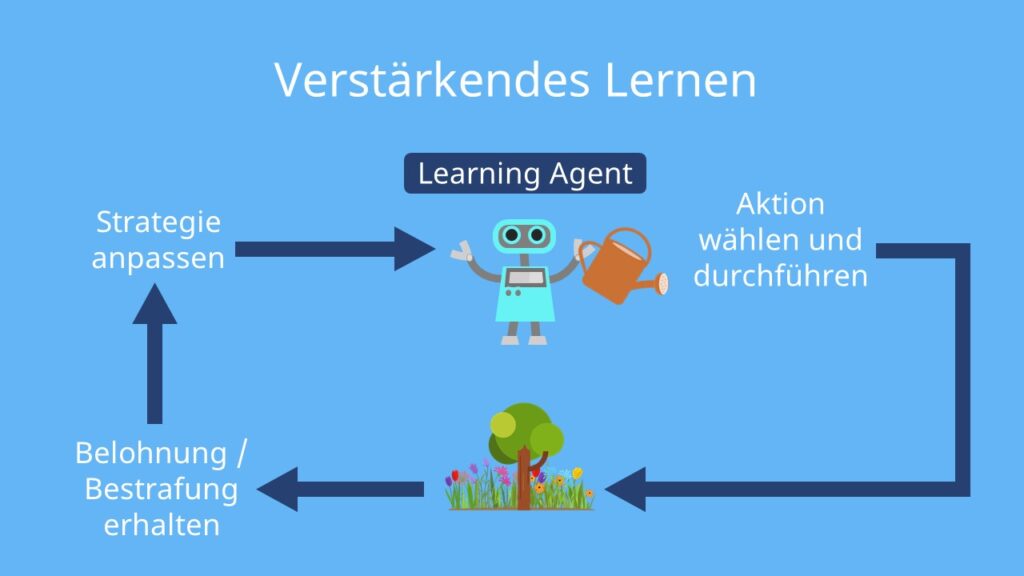
Bestärkendes Lernen (reinforcement learning)
- Mittels Belohnung und Bestrafung (Punktevergabe und Punkteabzug)
- Meist innerhalb einer Situation
- Wird oft in der Robotik eingesetzt
Aktives Lernen
Aktives Leren ist eine Unterkategorie des überwachten Lernens.
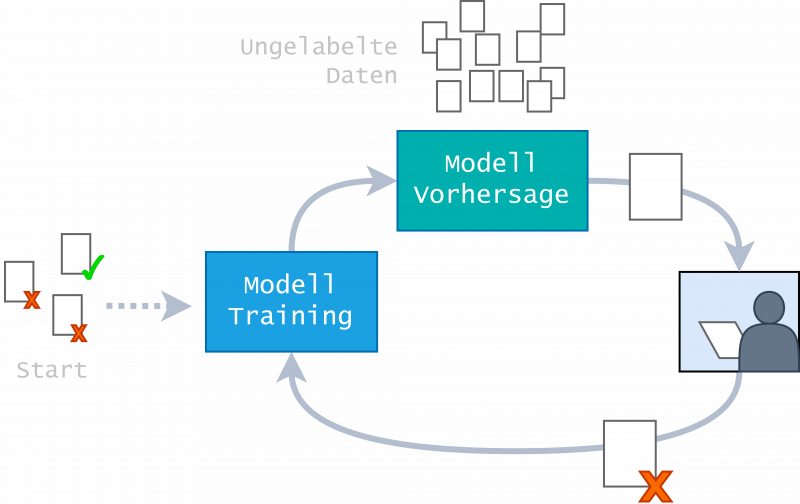
Aktives Lernen bezeichnet einen Lernalgorithmus, der Datenpunkte aus einer Menge an noch nicht gelabelten Datenpunkten gezielt auswählt, um sie als nächstes labeln zu lassen. Die Vergabe von Labels kann unter anderem von einem Menschen oder zu Evaluierungszwecken vom Algorithmus erfolgen.
Die Auswahl der Datenpunkte erfolgt nach einer Selektionsstrategie. Eine häufig gewählte Selektionsstrategie ist Uncertainty Sampling, das den Datenpunkt mit der geringsten Konfidenz auswählt. Die geringste Konfidenz bedeutet hierbei, dass der Algorithmus bei diesem Datenpunkt am wenigsten sicher ist, zu welcher Klasse dieser passt.
Der Grundgedanke ist, dass das Modell mit weniger Datenpunkten eine genauso hohe oder höhere Klassifikationsgenauigkeit (z.B. 90% richtig erkannt) erzielt wie ein Modell, das alle Datenpunkte nutzt. Wann der Lernprozess stoppt, wird über ein Stoppkriterium definiert.
Meta Lernen
Wenn ein Algorithmus lernt, liegt dieser Technik eine systematische Beobachtung zugrunde. Beim Meta-Learning oder dem „Lernen zu lernen“ geht es darum zu erkennen und zu adaptieren, wie verschiedene Ansätze des Maschinellen Lernens bei einer Vielzahl von bereits erledigten Lernaufgaben funktioniert haben.
Der Algorithmus kann so entscheiden, welche Lernmethoden für welche Art von Anwendungen am besten geeignet sind.
Anwendungen für Maschinelles Lernen
Clustering
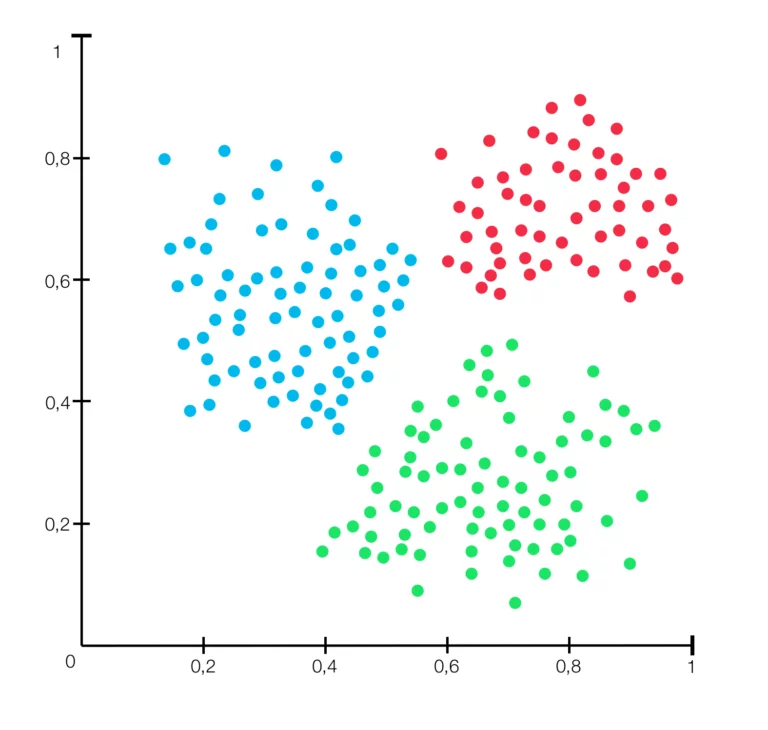
Clustering ist ein Verfahren des unüberwachten Lernens, bei dem Datenpunkte anhand ihrer Eigenschaften automatisch in Gruppen eingeteilt werden. Dabei kennt das Modell die Gruppen vorher nicht – es erkennt sie selbst durch Muster in den Daten.
Ein typischer Anwendungsfall ist die Erkennung von Spam-Bots in sozialen Medien. Diese Bots verhalten sich anders als echte Nutzer:innen: Sie posten extrem häufig, oft zu ungewöhnlichen Uhrzeiten (z. B. nachts um 3 Uhr) und verwenden wiederholt ähnliche Inhalte.
Wenn man diese Merkmale – z. B. „Posting-Häufigkeit“, „Uhrzeit“ und „Textlänge“ – als Zahlen darstellt, kann ein Clustering-Modell ähnliche Verhaltensmuster erkennen und die Bots von echten Nutzer:innen trennen.
In der Grafik sieht man drei Cluster: Jeder Punkt steht für ein Nutzerprofil, und die Farben zeigen, welche Gruppen das Modell erkannt hat. So lassen sich auffällige Muster sichtbar machen – ganz ohne vorherige Labels.
Klassifikation
Klassifikation ist ein Verfahren des überwachten maschinellen Lernens, bei dem Daten bestimmten, vorher bekannten Klassen zugeordnet werden. Ziel ist es, ein Modell zu trainieren, das anhand von Merkmalen erkennt, zu welcher Kategorie ein neuer Datenpunkt gehört. In der Bildanalyse wird Klassifikation häufig eingesetzt, um Objekte wie Pflanzen, Gebäude oder Landschaftsformen automatisch zu erkennen und zu unterscheiden.
Die gezeigten Bilder veranschaulichen diesen Prozess anhand von Baumarten. In den oberen Darstellungen sind abstrahierte Formen einzelner Bäume zu sehen, die typische Merkmale wie Kronenstruktur oder Umriss zeigen. Diese Merkmale dienen dem Modell als Grundlage, um Unterschiede zwischen Baumarten zu lernen. Die mittleren Bilder zeigen farbige Luftaufnahmen, in denen verschiedene Vegetationstypen sichtbar sind. Hier spielen Farbton, Textur und Flächenausdehnung eine Rolle bei der Unterscheidung.
Im unteren Bereich wird das Ergebnis der Klassifikation auf einer Karte dargestellt. Jeder Punkt steht für einen erkannten Baum, und die farblich markierten Flächen zeigen die Umgebung, etwa Wasserflächen oder bewachsene Gebiete. Die Zuordnung von Baumarten erfolgt auf Basis der zuvor gelernten Merkmale, sodass das Modell auch in neuen Gebieten automatisch erkennen kann, welche Baumart vorliegt.
Klassifikation ist besonders nützlich, wenn große Mengen an Bilddaten effizient ausgewertet werden sollen. In der Umweltforschung, Forstwirtschaft oder Stadtplanung hilft sie dabei, Informationen zu gewinnen, die sonst nur durch manuelle Analyse zugänglich wären.


Regression
Regression ist ein Verfahren des überwachten maschinellen Lernens, das verwendet wird, um kontinuierliche Werte vorherzusagen. Im Gegensatz zur Klassifikation, bei der Daten festen Kategorien zugeordnet werden, geht es bei der Regression darum, einen Zahlenwert zu schätzen – etwa die Temperatur am nächsten Tag, den Preis eines Produkts oder die Körpergröße einer Person.
Im gezeigten Diagramm ist Regression als Teilbereich des überwachten Lernens dargestellt, neben der Klassifikation. Die zugehörige Grafik zeigt eine Punktwolke, durch die eine Linie verläuft. Diese Linie – die sogenannte Regressionslinie – beschreibt den Zusammenhang zwischen zwei Variablen. Jeder Punkt steht für eine Beobachtung, und die Linie versucht, möglichst gut die Tendenz der Daten zu erfassen. Je näher die Punkte an der Linie liegen, desto besser passt das Modell.
Mathematisch betrachtet ist Regression oft gar nicht weit von der Klassifikation entfernt. Viele Algorithmen wie Entscheidungsbäume, künstliche neuronale Netze oder k-nächste-Nachbarn lassen sich mit kleinen Anpassungen sowohl für Klassifikation als auch für Regression einsetzen. Der Unterschied liegt vor allem im Ziel: Während Klassifikation eine Klasse vorhersagt, liefert Regression einen Zahlenwert.
Unterschiedlich ist jedoch der Zweck der Anwendung
In der Praxis ist Regression besonders nützlich, wenn man aus bekannten Daten neue Werte abschätzen möchte. Dabei ist wichtig zu verstehen, dass Regression keine Ursache-Wirkung-Beziehung beschreibt, sondern lediglich einen statistischen Zusammenhang. Sie zeigt, wie stark eine Variable mit einer anderen korreliert – nicht, ob sie sie verursacht.
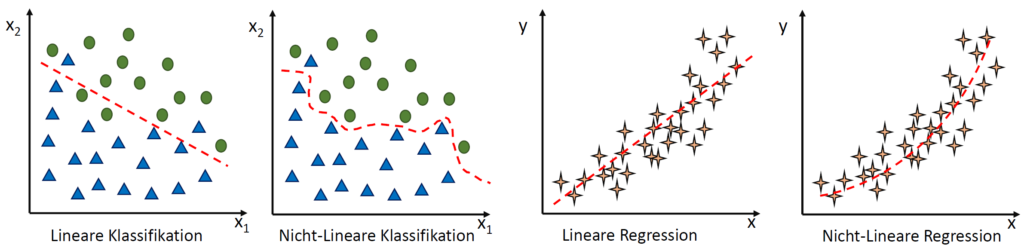
Bei der Klassifikation und Regression unterscheidet man zwischen linearen und nicht-linearen Verfahren: Lineare Modelle treffen Entscheidungen oder Vorhersagen entlang gerader Linien, während nicht-lineare Modelle komplexere, gekrümmte Zusammenhänge erfassen können. Egal welches Verfahren verwendet wird – die KI macht immer gewisse Fehler, die durch gutes Training und Testen zwar verringert, aber nie vollständig beseitigt werden können.
Aufgabe 1.4 Anwendung von Clustering, Klassifikation und Regression
Wähle eine der folgenden Methoden des maschinellen Lernens: Clustering, Klassifikation oder Regression und erkläre, wie sie in deinem gewählten Anwendungsbereich eingesetzt werden könnte.
Leitfragen zur Bearbeitung:
- Welche Art von Daten würde die Methode verarbeiten?
- Was wäre das Ziel: Gruppen bilden, Klassen zuordnen oder Werte vorhersagen?
- Welche konkreten Aufgaben könnte die Methode übernehmen?
- Warum ist diese Methode für den gewählten Bereich besonders geeignet?
Rechercheaufgabe
Aufgabe 1.5 KI in der echten Welt
Aufgabenstellung: Wähle ein konkretes Anwendungsfeld, in dem künstliche Intelligenz heute eingesetzt wird – z. B. Medizin, Verkehr, Bildung, Social Media, Justiz, Landwirtschaft oder Industrie.
Recherchiere dazu folgende Punkte:
- Wie funktioniert die KI in diesem Bereich? (z. B. Welche Daten werden verwendet? Was lernt das Modell?)
- Welche konkreten Aufgaben übernimmt die KI? (z. B. Diagnose, Steuerung, Empfehlung, Bewertung)
- Welche Chancen ergeben sich? (z. B. Effizienz, Sicherheit, neue Möglichkeiten)
- Welche Risiken oder ethischen Fragen entstehen? (z. B. Datenschutz, Diskriminierung, Verantwortung)
Präsentation: Bereite deine Ergebnisse als kurzes Poster, Mini-Vortrag oder digitale Präsentation auf. Ziel ist es, den anderen zu zeigen, wie KI in diesem Bereich wirkt – und was du persönlich davon hältst.