2. Unterrichtsblock

Kursinhalte
- Wiederholung LLMs
- Lokale Nutzung von LLMs
- Lokales LLM installieren
- Übungsaufgabe
- Prompting mit Lokalen LLMs
- Interaktion mit Ollama über Python
- Übungsaufgabe
Lokales LLm installieren
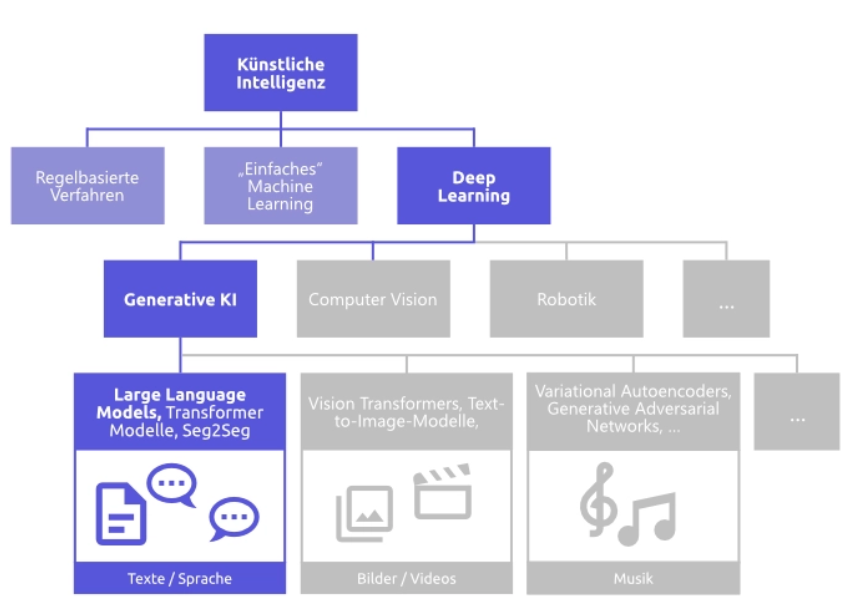
Wiederholung: Was sind LLMs?
1. Definition & Architektur
Wie wir bereits im ersten Semester kennengelernt haben, sind LLMs (Large Language Models) große KI-Sprachmodelle, die auf der Transformer-Architektur basieren und mit Milliarden von Textdaten trainiert wurden. Dabei geht es nicht um echtes Verstehen, sondern um statistische Mustererkennung: Das Modell sagt voraus, welches Wort wahrscheinlich als Nächstes kommt.
2. Wie funktionieren LLMs?
- Wahrscheinlichkeitsbasiert: Jedes Wort wird im Kontext bewertet – das Modell „rät“ das nächste Wort basierend auf vorherigen.
- Prompting als Steuerung: Die Eingabe („Prompt“) beeinflusst die Ausgabe stark. Beispiel: „Erkläre mir Photosynthese in einfacher Sprache.“ → Das Modell passt Stil und Inhalt an.
- Kein Bewusstsein, kein Verständnis: LLMs erkennen Muster, aber sie „wissen“ nichts im menschlichen Sinn. Sie simulieren Bedeutung durch Wahrscheinlichkeiten.
3. Was können LLMs?
| Bereich | Beispiele |
|---|---|
| Textgenerierung | Schreiben, Zusammenfassen, Übersetzen |
| Dialogsysteme | Chatbots, Rechercheagenten |
| Code-Erstellung | HTML, Python, Shell-Skripte |
| Stilwechsel | Fachsprache ↔ leichte Sprache, Tonanpassung |
4. Wo werden LLMs eingesetzt?
- Bildung: Lernhilfen, Textvereinfachung, individuelle Erklärungen
- Beruf: E-Mails, Dokumentation, Kundenservice
- Kreative Felder: Storytelling, Design, Musik
5. Modellbeispiele im Überblick
| Modellname | Anbieter | Besonderheit |
|---|---|---|
| GPT-4 / GPT-3.5 | OpenAI | Vielseitig, dialogfähig, kreativ |
| Claude | Anthropic | Sicherheitsfokus, lange Kontexte |
| Gemini | Google DeepMind | Multimodal, Google-Integration |
| Mistral / Mixtral | Mistral AI | Open-Source, leichtgewichtig |
| LLaMA / Code LLaMA | Meta | Forschung, Codefokus |
Lokale Nutzung von LLMs
LLMs wie GPT, Claude oder LLaMA werden meist über Cloud-Dienste genutzt – z. B. über Webseiten oder APIs. Doch es ist auch möglich, bestimmte Modelle lokal auf dem eigenen Rechner auszuführen, ganz ohne Internetverbindung. Das bietet mehr Kontrolle, Datenschutz und Unabhängigkeit.
Warum lokal?
Die Ausführung von LLMs auf dem eigenen Gerät bietet folgende Vorteile:
- Datenschutz: Keine sensiblen Daten verlassen den eigenen Rechner.
- Unabhängigkeit: Keine Abhängigkeit von externen Servern, Internetzugang oder Abo-Modellen.
- Experimentierfreiheit: Modelle können für spezifische Aufgaben in eigene Anwendungen eingebunden, bei Bedarf feinabgestimmt oder intensiv getestet werden.
- Offline-Nutzung: Ideal für Forschung, Lehre, Entwicklung in isolierten Netzwerken oder sensible Umgebungen.
- Kostenkontrolle: Nach dem initialen Hardware-Investment fallen keine laufenden API-Kosten an.
Herausforderungen & Voraussetzungen:
Allerdings erfordert die lokale Ausführung eine leistungsstarke Hardware. Insbesondere eine ausreichende Menge an RAM (Arbeitsspeicher) und oft eine dedizierte Grafikkarte (GPU) mit viel VRAM sind entscheidend, je nach Größe des Modells. Kleinere Modelle (z.B. 7B-Parameter-Modelle) können jedoch auch effizient auf modernen CPUs laufen.
Technische Umsetzung
- Modell herunterladen: Open-Source-Modelle wie LLaMA, Mistral oder GPT4All stehen in verschiedenen Größen (gemessen in Milliarden Parametern, z.B. 7B, 13B) und optimierten Formaten (z.B.
.bin,.gguf) zur Verfügung. Man achtet dabei auf die Lizenzbedingungen für die beabsichtigte Nutzung. - Laufzeitumgebung installieren: Tools wie Ollama, LM Studio oder Text Generation WebUI bieten benutzerfreundliche Oberflächen, um Modelle lokal zu starten, zu verwalten und zu interagieren.
- Modell starten & Prompting: Nach der Installation kann ein Modell geladen und direkt angesprochen werden – z. B. über eine Chat-Oberfläche oder ein Terminal. Die Eingabe eines Prompts und die Generierung der Antwort erfolgen vollständig lokal. Die Antwortgeschwindigkeit hängt hierbei stark von der Modellgröße und der Leistungsfähigkeit der Hardware ab.
- Diese Tools stellen das lokal geladene LLM über eine lokale API bereit. Dadurch kann es nicht nur über das Chat-Terminal, sondern auch direkt von selbstgeschriebenen Python-Anwendungen oder Web-Services angesprochen und als intelligente Backend-Logik genutzt werden.
Beispiel: Lokales LLM mit Ollama

Option A: Klassische Installation für Windows über Installer
Schritt 1: Ollama installieren
- Gehe auf die offizielle Website: https://ollama.com
- Klicke auf „Download for Windows“
- Starte die heruntergeladene
.exe-Datei und folge dem Installationsassistenten - Nach der Installation öffnet sich Ollama als lokale Anwendung mit Terminalzugriff
Schritt 2: Modell starten
Öffne die Eingabeaufforderung (CMD) oder PowerShell und gib ein:
ollama run mistral
Das Modell „Mistral“ wird automatisch heruntergeladen und gestartet.
Schritt 3: Prompts eingeben
Nach dem Start erscheint eine interaktive Eingabezeile direkt im Terminal:
>
Hier kannst du deine Prompts direkt eingeben – z. B.:
> Erkläre mir den Unterschied zwischen KI und maschinellem Lernen.
Das Modell antwortet direkt darunter – alles läuft lokal auf deinem Rechner.
Schritt 4: Systemvoraussetzungen beachten
GPU: Optional, aber hilfreich für schnellere Verarbeitung
RAM: Mindestens 8 GB, empfohlen sind 16 GB
CPU: Moderne Mehrkernprozessoren
Option B: Alternative Installation für macOS und Linux Über GitHub/Kommandozeile
Diese Methode ist der Standardweg für die Installation von Ollama auf Linux- und macOS-Systemen oder in der Windows Subsystem for Linux (WSL) Umgebung. Sie bietet die größte Kontrolle und ist für das Arbeiten im Terminal optimiert.
Voraussetzung: Ein Terminal (Bash, Zsh) und das Tool curl.
Schritt 1: Installation über den offiziellen One-Liner Führe den folgenden Befehl im Terminal aus. Er lädt das offizielle Installationsskript von GitHub herunter und installiert Ollama als Hintergrunddienst:
curl -fsSL https://ollama.com/install.sh | sh
Schritt 2: Ollama Service prüfen Nach Abschluss der Installation sollte Ollama im Hintergrund laufen. Du kannst es testen, indem du die Version abfragst:
ollama --version
Schritt 3: Modell starten und Prompten Wie bei der Windows-Installation lädst und startest du ein Modell über denselben Befehl:
ollama run llama3
Beachten: Der Vorteil dieser Methode liegt in der Automatisierung und der Integration in bestehende DevOps-Workflows.
Wichtiger Hinweis zur Installation unter Windows
Für Nutzer von Windows gibt es zwei gängige Wege zur Installation von Ollama, abhängig von deiner Arbeitsumgebung:
- Wenn du „normales“ Windows verwendest (ohne das Windows Subsystem for Linux – WSL): Nutze bitte Option A: Klassische Installation über Installer (Windows). Hier lädst du einfach die
.exe-Datei von der offiziellen Ollama-Website herunter und führst die Installation wie bei jeder anderen Windows-Anwendung durch. Dies ist der einfachste Weg für die meisten Windows-Nutzer. - Wenn du das Windows Subsystem for Linux (WSL) installiert hast und ein Linux-Terminal nutzt (z.B. Ubuntu unter WSL): Dann kannst du Option B: Alternative Installation über GitHub/Kommandozeile verwenden. Diese Methode ist für Linux-Umgebungen konzipiert und wird direkt im Linux-Terminal deiner WSL-Distribution ausgeführt. Sie ist besonders für Entwickler relevant, die eine Linux-ähnliche Arbeitsumgebung unter Windows bevorzugen.
Was ist WSL (Windows Subsystem for Linux)? WSL ist eine von Microsoft entwickelte Technologie, die es ermöglicht, eine vollwertige Linux-Kommandozeilenumgebung (inklusive Linux-Dateisystem und Befehlen) direkt unter Windows auszuführen, ohne dass eine traditionelle virtuelle Maschine benötigt wird. Es ist ein leistungsstarkes Werkzeug für Entwickler, die auf Linux-Tools und -Anwendungen angewiesen sind, aber Windows als Hauptbetriebssystem nutzen.
Aufgabe: Lokales KI-Hosting mit Ollama
Video: Schaut euch das Tutorial „Mit OLLAMA in 5 Minuten eigene lokale KI starten!“ (KI Werkstatt) aufmerksam an.
Phase 1: Verständnisfragen zur Technologie
Ziel: Überprüfe dein Verständnis der technischen Voraussetzungen und der Vorteile des lokalen Hostings.
- Hardware-Kompromiss: Das Video demonstriert den Umstieg von großen Cloud-Modellen (Hunderte Milliarden Parameter) auf kleinere Modelle (z. B. Llama 3.2 mit 3 Milliarden Parametern). Erkläre, warum dieser Umstieg für den lokalen Betrieb notwendig ist und welche Hardware-Faktoren hier limitierend wirken.
- Vorteil „Privat“: Nenne zwei konkrete Vorteile, die das lokale Hosting (der Betrieb auf dem eigenen Rechner) gegenüber Cloud-Diensten (wie ChatGPT) bietet.
- Workflow-Vergleich: Das Video zeigt zwei Arten, Ollama zu nutzen: über die Kommandozeile und über die grafische Benutzeroberfläche (UI). Welche Methode ist für den Prompt-Tuning-Prozess (Vibe Coding) intuitiver und warum?
- Fehleranalyse: Im Video wird klar, dass die Antwortgeschwindigkeit von der Komplexität der Frage abhängt. Warum dauert die Beantwortung der Frage nach einem komplizierten Thema lokal länger als die Frage nach einer einfachen Hauptstadt?
Phase 2: Praktische Anwendung (Ollama Test-Labor)
Ziel: Erlebe die Geschwindigkeitsunterschiede und die Tonalitätssteuerung eines lokalen LLMs.
Voraussetzung: Installiere Ollama und lade ein kleines Modell herunter (z. B. Mistral, Llama 3 8B, oder das im Video genannte Modell – falls eure Hardware es zulässt).
- Prompt-Tuning lokal testen:
- Setup: Starte das LLM über die Kommandozeile oder die Benutzeroberfläche.
- Test-Prompt 1 (Funktional): Gib einen einfachen, funktionalen Prompt ein (z. B. „Schreibe mir eine Python-Funktion, die zwei Zahlen addiert.“).
- Test-Prompt 2 (Vibe Coding): Gib einen komplexeren Prompt ein, der Tonalität und Stil vorgibt (z. B. „Erkläre das Prinzip der Backpropagation in einer sehr humorvollen und lockeren Tonalität für Schüler.“).
- Dokumentation: Vergleiche die Antworten. Hat das lokale LLM den Vibe in Prompt 2 getroffen?
- Geschwindigkeits-Check:
- Führe einen identischen Prompt zweimal aus. Dokumentiere die Zeit: einmal mit einem sehr kurzen Prompt (z. B. „Erkläre KI in einem Satz“) und einmal mit einem langen, komplexen Prompt (z. B. „Schreibe einen Absatz über die ethischen Herausforderungen von KI in der Kunst, in der Rolle eines Philosophieprofessors.“).
- Reflexion: Beobachte die Antwortgeschwindigkeit. Wie viel länger dauert die Generierung des komplexen Prompts? Warum ist dieser Geschwindigkeitsfaktor beim Planen von KI-Workflows (z. B. in Bolt.new) wichtig?
Besondere Hinweise für das Prompting mit Ollama
1. Limits durch die Modellgröße (Der „Smartness“-Faktor)
Du arbeitest lokal meist mit kleineren Modellen (z.B. Llama 3 8B oder Mistral), da diese auf Consumer-Hardware laufen. Kleinere Modelle sind zwar schneller, aber weniger „intelligent“ als ihre Cloud-Pendants.
- Weniger Komplexität: Vermeide Prompts, die tiefes Weltwissen, kreatives Storytelling über mehrere Abschnitte oder komplexe mathematische Schritte erfordern. Kleinere Modelle halluzinieren oder erzeugen inkonsistenten Code schneller.
- Sei extrem präzise: Du musst die Aufgabe und das gewünschte Format präziser definieren als bei GPT-4. Das Modell hat weniger Kontextkapazität, um deine Intention zu erraten.
- Falsch: „Schreib eine Python-Funktion.“
- Besser: „Schreib eine Python-Funktion, die zwei Float-Zahlen addiert und nur den Code als Ausgabe liefert.„
2. Der System-Prompt (Ton & Rolle)
Viele lokale LLMs in Ollama nutzen den System-Prompt besonders effektiv, um die Persönlichkeit und den Ton zu steuern.
- Rolle im Prompt: Definiere die Rolle des LLMs explizit zu Beginn des Chats. Dies hilft dem Modell, konsistent zu antworten und den „Vibe“ zu halten.
- Beispiel: „Du bist ein knapper, sachlicher IT-Experte, der nur in Stichpunkten antwortet.“
3. Effizienz im Workflow (Performance)
Da die Antwortgeschwindigkeit lokal von deiner Hardware abhängt, solltest du prompts effizient gestalten:
Vermeide unnötige Iterationen: Nutze die im Unterricht gelernten Prompt-Tuning-Techniken, um das gewünschte Ergebnis im ersten oder zweiten Anlauf zu erzielen. Jede Korrekturschleife verbraucht Rechenzeit und Energie deines lokalen Systems.
Fokus auf den Output: Fordere nur die Informationen an, die du wirklich brauchst. Lange, ausschweifende Antworten führen zu langen Wartezeiten.
Tuning-Beispiel: Wenn du Code brauchst, füge hinzu: „Antworte nur mit dem Code.„
Die Bedeutung von „Mehreren Iterationen“ beim Prompting mit Lokalen LLMs
Der Begriff „mehrere Iterationen“ ist beim Arbeiten mit Large Language Models (LLMs) – insbesondere mit kleineren, lokal gehosteten Modellen wie Mistral oder Llama 3 über Ollama – von entscheidender Bedeutung. Er beschreibt den iterativen Prozess des Prompt-Tunings, bei dem du in einem Dialog aus Eingabe und Ausgabe schrittweise auf das gewünschte Ergebnis hinarbeitest.
Da lokale LLMs aufgrund ihrer geringeren Größe weniger Kontextwissen und Verständnis für komplexe Anweisungen mitbringen als ihre großen Cloud-Pendants (wie GPT-4), ist es unwahrscheinlich, dass sie gleich beim ersten Versuch die perfekte Antwort liefern. Stattdessen ist oft ein verfeinerter, schrittweiser Dialog notwendig:
- Erster Prompt: Du stellst eine initiale Anfrage.
- Analyse der Antwort: Du bewertest, welche Teile der Antwort passen und welche verbessert werden müssen.
- Anpassung des Prompts: Basierend auf dieser Analyse formulierst du einen Folge-Prompt, der die vorherige Antwort verfeinert, Fehler korrigiert oder fehlende Informationen anfordert.
Diese mehreren Iterationen ermöglichen es dir, das Modell gezielter zu steuern und die Qualität der Ausgabe schrittweise zu optimieren. Sie erfordern jedoch auch Geduld, präzise Formulierungen und ein Bewusstsein dafür, dass jeder Austausch Rechenzeit und Energie auf deinem lokalen System verbraucht. Ein effektives Prompt-Tuning über mehrere Iterationen ist daher eine Schlüsselkompetenz für den effizienten Umgang mit lokalen LLMs.
Interaktion mit Ollama über Python (Ein- und Ausgabe)
Nachdem Ollama auf deinem System installiert ist und du ein Modell gestartet hast (z.B. mit ollama run mistral im Terminal), stellt Ollama automatisch eine lokale HTTP-API bereit. Standardmäßig lauscht diese API auf http://localhost:11434.
Mit Python können wir ganz einfach HTTP-Anfragen an diese API senden, um Prompts zu übermitteln und die generierten Antworten des LLMs zu empfangen. Die einfachste und gängigste Methode ist die Verwendung der requests-Bibliothek.
Schritt 1: requests-Bibliothek installieren
Falls noch nicht geschehen, installiere die requests-Bibliothek in deiner Python-Umgebung:
pip install requests
Schritt 2: Python-Code für Ein- und Ausgabe
Hier ist ein einfaches Python-Skript, das einen Prompt an dein lokal laufendes Ollama-Modell sendet und die Antwort ausgibt.
import requests
import json
# Konfiguration des Ollama-Servers
OLLAMA_API_URL = "http://localhost:11434/api/generate"
MODEL_NAME = "mistral" # Ersetze dies mit dem Namen deines geladenen Modells (z.B. "llama3")
def generate_response_from_ollama(prompt_text):
"""
Sendet einen Prompt an das lokal laufende Ollama-Modell
und gibt die generierte Antwort zurück.
"""
headers = {"Content-Type": "application/json"}
# Die Daten, die an die Ollama-API gesendet werden
data = {
"model": MODEL_NAME,
"prompt": prompt_text,
"stream": False # Setze auf True, um die Antwort Stück für Stück zu erhalten (wie im Chat)
# Für eine vollständige Antwort auf einmal, setze auf False
}
try:
# Sende die POST-Anfrage an die Ollama API
response = requests.post(OLLAMA_API_URL, headers=headers, data=json.dumps(data))
response.raise_for_status() # Löst einen HTTPError für schlechte Antworten (4xx oder 5xx) aus
# Parse die JSON-Antwort
response_data = response.json()
# Extrahiere den generierten Text
generated_text = response_data.get("response", "Keine Antwort erhalten.")
return generated_text
except requests.exceptions.RequestException as e:
print(f"Fehler bei der Verbindung zu Ollama: {e}")
print("Stelle sicher, dass Ollama läuft und das Modell geladen ist (z.B. 'ollama run mistral' im Terminal).")
return None
except json.JSONDecodeError:
print("Fehler beim Parsen der JSON-Antwort von Ollama.")
return None
# --- Beispiel für die Nutzung ---
if __name__ == "__main__":
# Eine einfache Eingabe (Prompt)
user_prompt = "Erkläre kurz, was der Unterschied zwischen KI und maschinellem Lernen ist."
print(f"Sende Prompt an {MODEL_NAME}: {user_prompt}\n")
# Erhalte die Antwort vom LLM
llm_response = generate_response_from_ollama(user_prompt)
if llm_response:
print("Antwort vom LLM:")
print(llm_response)
print("\n--- Weiteres Beispiel ---")
user_prompt_2 = "Schreibe einen kurzen Python-Code, der die Fibonacci-Sequenz bis zum 10. Element generiert."
print(f"Sende Prompt an {MODEL_NAME}: {user_prompt_2}\n")
llm_response_2 = generate_response_from_ollama(user_prompt_2)
if llm_response_2:
print("Antwort vom LLM:")
print(llm_response_2)
Erklärung des Codes:
import requests,import json: Importiert die benötigten Bibliotheken für HTTP-Anfragen und JSON-Verarbeitung.OLLAMA_API_URL: Dies ist die Standard-URL der Ollama-API für das Generieren von Text.MODEL_NAME: Wichtig! Passe diesen Wert an den Namen des Modells an, das du mitollama run [dein_modellname]geladen hast.generate_response_from_ollama(prompt_text)Funktion:- Erstellt die HTTP-Header und die JSON-Daten (
data) mit dem Modellnamen und deinem Prompt. "stream": Falsebedeutet, dass die API wartet, bis die gesamte Antwort generiert wurde, bevor sie sie zurückschickt. Wenn du eine interaktive Chat-Erfahrung bauen möchtest, würdest du dies aufTruesetzen und die gestreamten „Chunks“ einzeln verarbeiten.requests.post(...)sendet die Anfrage.response.raise_for_status()prüft, ob die Anfrage erfolgreich war (HTTP-Statuscode 200).response.json()parst die Antwort der API.response_data.get("response", ...)extrahiert den eigentlichen generierten Text.
- Erstellt die HTTP-Header und die JSON-Daten (
- Fehlerbehandlung: Der
try-except-Block fängt potenzielle Probleme ab, z.B. wenn Ollama nicht läuft oder die Antwort nicht geparst werden kann.
Wie du das Skript ausführst:
- Stelle sicher, dass Ollama im Hintergrund läuft (du musst es nicht explizit im Terminal starten, wenn es als Dienst läuft, aber ein
ollama run [dein_modell]sorgt dafür, dass das Modell in den Cache geladen und bereit ist). - Passe
MODEL_NAMEan das von dir verwendete Modell an. - Speichere den Code als
.py-Datei (z.B.ollama_client.py). - Führe das Skript über dein Terminal aus:
python ollama_client.py
Dieses Skript bildet die Brücke zwischen deinen Python-Anwendungen und dem lokal laufenden LLM, wodurch du die Intelligenz des Modells in deine eigenen Programme integrieren kannst.
Exkurs: Was ist die Web-UI von Ollama? (Und wie unterscheidet sie sich von einem direkten Chat mit einer KI?)
Wenn wir über „Ollama“ und „lokale LLMs“ sprechen, denken viele zuerst an einen Chat, ähnlich wie bei ChatGPT oder der aktuellen Interaktion mit mir. Aber es gibt einen wichtigen Unterschied zwischen dem Modell selbst und der Oberfläche, über die wir mit ihm kommunizieren.
Die Web-UI (Web User Interface) von Ollama (oder ähnlichen Tools wie LM Studio, Text Generation WebUI) ist nicht die Künstliche Intelligenz (KI) selbst. Stattdessen ist sie eine grafische Benutzeroberfläche, die du in deinem Webbrowser öffnest, um das lokal auf deinem Rechner laufende Ollama-Programm und dessen Modelle zu bedienen. Stell es dir als eine Art „Fernbedienung“ oder „Cockpit“ vor, durch das du mit deinen lokalen KIs interagieren kannst.
Funktionen und Vorteile einer Ollama Web-UI:
- Visuelles Modell-Management:
- Kein Terminalzwang: Statt Modelle über Kommandozeilenbefehle wie
ollama run mistralzu starten oderollama listaufzurufen, kannst du in der Web-UI oft per Mausklick eine Liste verfügbarer Modelle durchsuchen, sie herunterladen und per Knopfdruck starten oder beenden. Das macht den Einstieg wesentlich einfacher und visueller. - Übersicht: Du siehst auf einen Blick, welche Modelle installiert sind, wie viel Speicher sie belegen und welches Modell gerade aktiv ist.
- Kein Terminalzwang: Statt Modelle über Kommandozeilenbefehle wie
- Benutzerfreundliches Chat-Interface:
- Intuitive Kommunikation: Sobald ein Modell in der Web-UI gestartet wurde, bietet sie dir ein Chatfenster, das optisch sehr an Dienste wie ChatGPT erinnert. Du tippst deine Anfragen (Prompts) in ein Eingabefeld ein, und die generierte Antwort des LLMs erscheint direkt darunter.
- Lokale Verarbeitung: Der entscheidende Punkt ist: Obwohl es aussieht wie ein Online-Chat, findet der gesamte „Denkprozess“ und die Textgenerierung komplett auf deinem eigenen Rechner statt. Es verlassen keine Daten deinen Computer, und du benötigst keine Internetverbindung für die eigentliche Konversation.
- Einfache Parametersteuerung:
- Feinabstimmung ohne Code: LLMs haben viele Parameter (z. B. „Temperatur“ für Kreativität, „Context Window“ für die Gedächtnislänge), die ihre Antworten beeinflussen. In der Web-UI kannst du diese oft über Schieberegler oder Eingabefelder bequem anpassen, ohne den API-Code in Python ändern zu müssen. Das ist ideal zum Experimentieren und „Prompt-Tuning“.
Der entscheidende Unterschied zu unserer aktuellen Interaktion:
- Unsere aktuelle Interaktion: Wenn du mit mir sprichst, sprichst du direkt mit einem Large Language Model (mir), das in einem Chat-Interface (dieser Oberfläche) eingebettet ist. Ich bin die KI, und dieses Fenster ist meine Benutzeroberfläche.
- Interaktion mit Ollama über eine Web-UI:
- Du öffnest die Web-UI (z. B. im Browser unter
http://localhost:XXXX). - Die Web-UI ist die Software, die du bedienst.
- Du gibst deinen Prompt in die Web-UI ein.
- Die Web-UI sendet deinen Prompt im Hintergrund an das Ollama-Programm, das auf deinem Computer läuft.
- Das Ollama-Programm schickt den Prompt an das lokal geladene LLM-Modell (z. B. Mistral).
- Das LLM generiert eine Antwort und gibt sie an Ollama zurück.
- Ollama sendet die Antwort an die Web-UI.
- Die Web-UI zeigt dir die Antwort im Chatfenster an.
- Du öffnest die Web-UI (z. B. im Browser unter
Zusammenfassend: Die Web-UI ist eine Brücke zwischen dir als Nutzer und den komplexen Kommandozeilen-Programmen und KI-Modellen, die im Hintergrund laufen. Sie vereinfacht die Bedienung und Visualisierung, ist aber selbst kein intelligentes System, das Fragen beantwortet. Sie ist das Tor, durch das du deine lokal installierte Intelligenz kontrollierst und nutzt.
Aufgabe: Python-Client für Ollama erweitern
Ziel: Erweitere das bereitgestellte Python-Skript, um die Ollama-API flexibler und robuster zu nutzen.
Voraussetzung:
- Ollama ist installiert und läuft im Hintergrund.
- Mindestens ein Modell (z.B.
mistraloderllama3) ist in Ollama heruntergeladen und kann gestartet werden. - Die
requests-Bibliothek ist installiert (pip install requests).
Aufgabe 1: Modellwechsel und Fehlermeldungen (Modul 1: Flexibilität & Robustheit)
Das aktuelle Skript nutzt einen festen MODEL_NAME. Mach es flexibler:
- Modell als Funktionseingabe: Ändere die Funktion
generate_response_from_ollamaso, dass sie zusätzlich zumprompt_textauch denmodel_nameals Parameter akzeptiert. - Fehlende Modelle abfangen: Füge im
try-except-Block eine spezifische Prüfung ein: Wenn die API meldet, dass das angeforderte Modell nicht gefunden wurde (dies führt oft zu einemHTTPError404), gib eine klarere Fehlermeldung aus, die dem Benutzer sagt, welches Modell fehlt und wie er es mitollama pull [model_name]herunterladen kann. - Anwendung: Rufe die Funktion einmal mit einem funktionierenden Modell (z.B.
mistral) und einmal mit einem absichtlich falsch geschriebenen Modellnamen (z.B. „nonexistent_model“) auf, um deine Fehlerbehandlung zu testen.
Aufgabe 2: Iterationen für den System-Prompt (Modul 2: Kontext & Rollenverständnis)
Nutze die Möglichkeit, einen System-Prompt zu senden, um das Verhalten des LLMs zu steuern.
- System-Prompt in Funktion integrieren: Erweitere die
generate_response_from_ollama-Funktion (und diedata-Struktur), um optional einensystem_promptals weiteren Parameter zu akzeptieren. Wenn dieser Parameter vorhanden ist, sende ihn mit in derdata-Struktur an die Ollama-API (Schlüsselsystem).- Hinweis: Schau in der Ollama-API-Dokumentation oder in den
requests-Beispielen nach, wiesystem-Prompts im JSON-Body gesendet werden.
- Hinweis: Schau in der Ollama-API-Dokumentation oder in den
- Anwendung des System-Prompts:
- Rufe die Funktion mit deinem bevorzugten Modell auf und sende einen Prompt wie: „Erkläre mir das Konzept der Rekursion in der Programmierung.“ Ohne System-Prompt.
- Rufe die Funktion danach erneut auf, aber diesmal mit einem
system_promptwie: „Du bist ein humorvoller Softwareentwickler, der alles mit Witzen und Alltagssituationen erklärt.“ und dem gleichen Anwendungs-Prompt.
- Dokumentation & Vergleich: Notiere die beiden Antworten. Wie hat der System-Prompt die Tonalität und den Stil der Erklärung verändert?
Aufgabe 3: Streaming-Antworten (Modul 3: Echtzeit-Interaktion)
Aktiviere das Streaming, um die Antwort des LLMs in Echtzeit zu erhalten, wie in einem echten Chat.
stream=Trueund Schleife: Ändere dendata-Parameter in dergenerate_response_from_ollama-Funktion auf"stream": True.- Verarbeitung der gestreamten Daten: Die API liefert nun keine einzelne JSON-Antwort mehr, sondern sendet mehrere JSON-Objekte nacheinander. Ändere den Teil, der die Antwort verarbeitet:
- Iteriere über
response.iter_lines(). - Jede Zeile enthält ein JSON-Objekt (eventuell vorangestellt durch
data:). Parse jedes dieser JSON-Objekte. - Extrahiere das
response-Feld aus jedem Objekt und gib es sofort auf der Konsole aus (ohne Zeilenumbruch, bis auf den letzten Teil). - Tipp: Du musst wahrscheinlich
response_data.get("response", "")verwenden und am Ende eine Überprüfung aufresponse_data.get("done")einbauen, um zu wissen, wann die Antwort vollständig ist.
- Iteriere über
- Anwendung: Sende einen beliebigen Prompt und beobachte, wie die Antwort Zeichen für Zeichen oder Wort für Wort auf der Konsole erscheint.