3. Unterrichtsblock

Kursinhalte
Prompt-Design & Prompt-Engineering bei LLMs
@Unterrichtsvorbereitung: folgende Inhalte einbauen: https://cloud.google.com/discover/what-is-prompt-engineering
Prompt-Design

Ein Prompt (deutsch „Anweisung“) ist die Eingabe, die einem KI-Modell gegeben wird, um eine Antwort zu generieren. Ein Prompt ist daher der Start einer Konversation oder Aufgabe. Gute Prompts helfen dir, die volle Leistung der KI zu nutzen. Dafür gibt es vier wichtige Bausteine:
- Aufgabe Was soll die KI tun? → Beispiel: „Erkläre mir, wie ein Elektromotor funktioniert.“
- Kontext Welche Hintergrundinfos braucht die KI? → Beispiel: „Ich bin Berufsschüler im ersten Lehrjahr.“
- Beispiele Was ist ein gutes Beispiel für die gewünschte Antwort? → Beispiel: „So ähnlich wie bei der Erklärung zum Verbrennungsmotor.“
- Format In welcher Form soll die Antwort kommen? → Beispiel: „Bitte als Liste mit kurzen Stichpunkten.“
Du kannst der KI auch eine Rolle geben – z. B. „Du bist ein Französischlehrer“ oder „Du bist ein Programmierer“. Das hilft der KI, die Aufgabe besser zu verstehen. Du kannst auch sagen, wie die Antwort aussehen soll – z. B. als Liste, Tabelle, Drehbuch oder Code.
Tipp: Du kannst Markdown-Sprache verwenden, um das Format zu bestimmen. Das Format hängt davon ab, wofür du die Antwort brauchst.
- Listen und Tabellen sind gut für Menschen
- Code und Daten sind gut für Computer
Prompting ist ein Gespräch, das sich entwickelt. Du kannst mehrere Prompts verwenden und immer wieder neue Infos hinzufügen, bis du das Ergebnis bekommst, das du willst. Wenn Menschen mit GenAI arbeiten und die Antworten verbessern, nennt man das Human-in-the-Loop.
Beispiele
Ungenauer Prompt: „Baue mir ein Haus“
Mögliches Ergebnis

Ausführlicher Prompt: „Baue mir ein Haus im Toskana-Stil mit einem einstöckigem Turm mit Balkon, beige Säulen im Eingangsbereich und einem Teich davor. Zusätzlich sollen zwei Pinien, die in einem Lavendelbeet stehen den Eingangsweg säumen.“
Wahrscheinliches Ergebnis

Prompt-Engineering
Um die Ausgabe so gut wie möglich zu gestalten, nutzt man sogenanntes Prompt-Engineering. Hierbei werden die Anweisungen konkretisiert, um das gewünschte Ergebnis zu verbessern.
10 Tipps, die dir helfen, deine Eingaben zu verbessern:
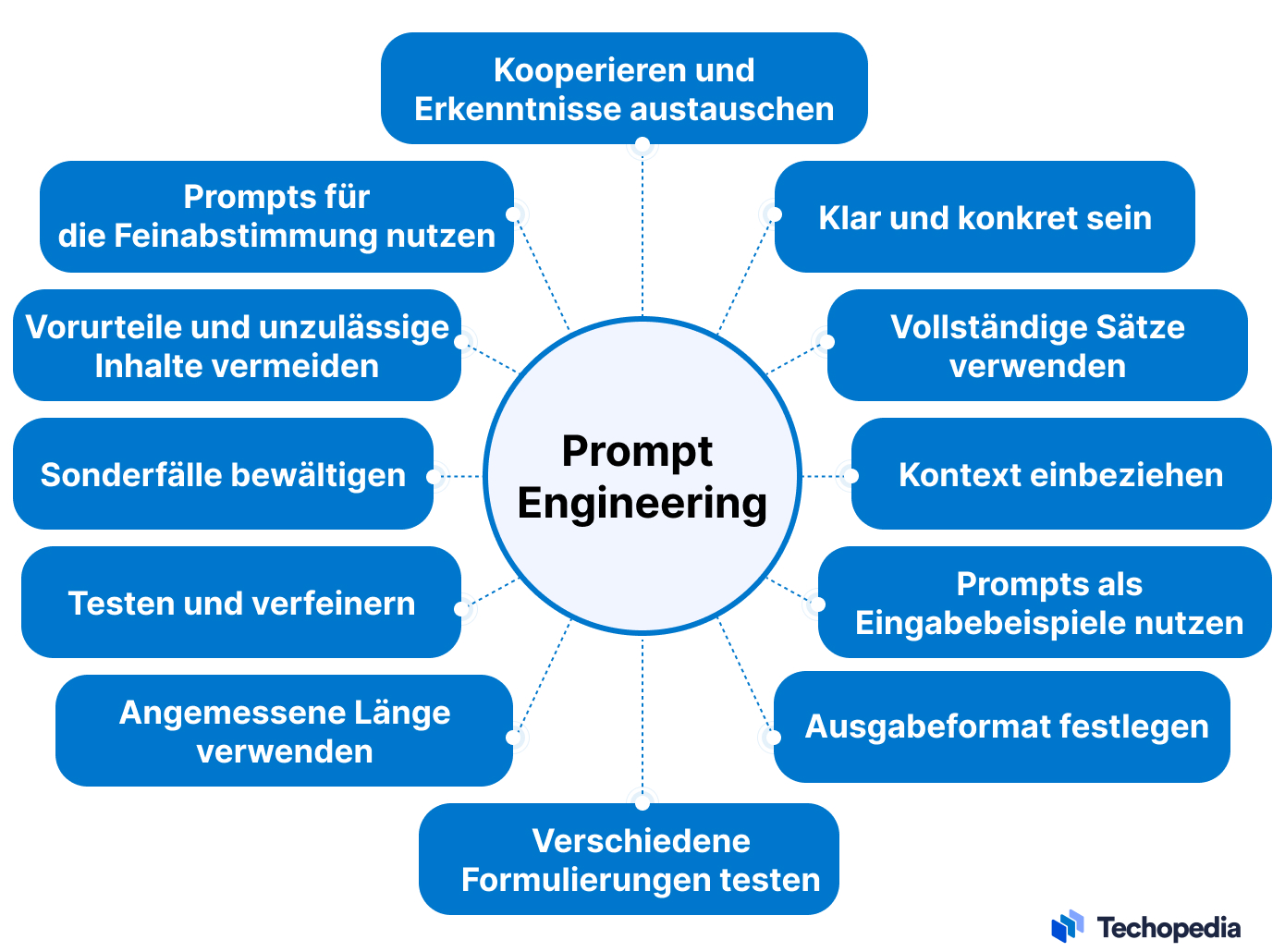
Arten von Prompts im Prompt Engineering
| Prompt-Art | Erklärung in einfacher Sprache |
|---|---|
| Zero-Shot Prompt | Die KI bekommt nur die Aufgabe – ohne Beispiel. Funktioniert oft überraschend gut. |
| Few-Shot Prompt | Die KI bekommt die Aufgabe mit ein oder mehreren Beispielen. Das hilft beim Verstehen. |
| Chain-of-Thought Prompt | Die KI wird gebeten, Schritt für Schritt zu denken. Gut für Mathe, Logik und komplexe Aufgaben. |
| Instruction Prompt | Die Eingabe ist wie eine klare Anweisung: „Erkläre mir…“, „Schreibe einen Text über…“ |
| Role-based Prompt | Die KI bekommt eine Rolle: z. B. „Du bist ein Lehrer“, „Du bist ein Programmierer“ |
| System Prompt | Wird intern verwendet, um die KI zu steuern – z. B. wie höflich oder sachlich sie antwortet |
| Multi-turn Prompt | Eine mehrteilige Unterhaltung – die KI erinnert sich an vorherige Fragen und Antworten |
| ReAct Prompt | Kombiniert Denken (Reasoning) und Handeln (Acting) – z. B. bei Rechercheaufgaben |
| Self-Ask Prompt | Die KI stellt sich selbst Zwischenfragen, um komplexe Aufgaben besser zu lösen |
| Template Prompt | Eine Vorlage, die du mehrfach verwenden kannst – z. B. für ähnliche Aufgaben oder Schülergruppen |
Aufgabe
- Schreibe einen einfachen Prompt „Welche verschiedenen Arten von Prompts gibt es?“
- Diskutiere in kleinen Gruppen, wie der Prompt verbessert werden kann, um das Ergebnis zu verbessern. Was fehlt z. B. am Ergebnis, um auch Personen ohne Sachkenntnis zu erklären, worüber gerade gesprochen wird?
- Verbessere und erweitere den Prompt, indem spezifischere Angaben gemacht werden, um das Ergebnis zu verbessern
- Ändert oder fügt neue Elemente zu den bestehenden Prompts hinzu, um zu sehen, wie sich die Antworten verändern (z.B. Art der Erklärung (Zielgruppe) ändern, Regeln hinzufügen).
- Schreibt eine kurze Reflexion: Was habt ihr durch diese Übung über die Bedeutung von klaren und kreativen Prompts gelernt?
Token
Ein Token ist ein kleiner Baustein, den ein KI-Modell wie ChatGPT verwendet, um Sprache zu verarbeiten. Ein Token kann ein Wort, ein Teil eines Wortes oder sogar ein Satzzeichen sein.
Beispiel: Der Satz „Ich lerne KI.“ besteht aus 4 Tokens: „Ich“, „lerne“, „KI“, „.“
Die Länge einer Eingabe und Ausgabe wird oft in Tokens gemessen.
Wenn du mit KI arbeitest, musst du wissen, dass:
- Jeder Prompt und jede Antwort aus Tokens besteht
- Die KI hat ein Token-Limit – also eine maximale Länge für Eingabe und Ausgabe
- Zu lange Prompts können dazu führen, dass die Antwort abgeschnitten wird
- Je klarer und kompakter dein Prompt, desto effizienter nutzt du die verfügbaren Tokens

Unterschied zwischen Input- und Output-Tokens
Input Tokens
- Definition: Input Tokens sind die Teile des Textes, die in das Modell eingespeist werden, um verarbeitet zu werden.
- Funktion: Sie dienen als Basis, auf der das Modell seine Berechnungen durchführt, um eine Antwort oder eine Vorhersage zu generieren.
- Beispiele: Wenn ein Satz wie „Der Himmel ist blau“ eingegeben wird, könnte das Modell diesen Satz in Tokens wie „Der“, “ Himmel“, “ ist“, “ blau“ zerlegen, je nach Tokenisierungsstrategie. Jede dieser Einheiten wird dann als einzelnes Input Token fungieren.
- Verarbeitung: Das Modell verwendet diese Tokens, um sprachliche Muster zu erkennen und zu verstehen, welche Bedeutung in dem gegebenen Kontext steckt.
Tokenzähler: https://llmtokencounter.com/
Output Tokens
- Definition: Output Tokens sind die Teile des Textes, die das Modell erzeugt, nachdem es die Input Tokens verarbeitet hat.
- Funktion: Sie sind das Ergebnis der Verarbeitung und geben die modellgenerierte Antwort, Vorhersage oder Fortsetzung des Textes wieder.
- Beispiele: Nach der Verarbeitung der Input Tokens könnte das Modell eine Antwort wie „und die Sonne scheint“ generieren, wobei auch diese Ausgabe in Tokens zerlegt wird – z.B. „und“, “ die“, “ Sonne“, “ scheint“.
- Generierung: Das Modell erzeugt diese Tokens iterativ, basierend auf Wahrscheinlichkeitsbewertungen, die es für den nächsten Token im Kontext des bisher erzeugten Textes vornimmt.
Wichtiges zur Token-Verarbeitung
- Tokens sind nicht immer gleich Worte; ein einzelnes Wort kann in mehrere Tokens aufgeteilt werden, insbesondere bei der Verwendung von Byte-Pair Encoding (BPE) oder anderen Tokenisierungsverfahren, die Subworte oder Zeichenfolgen als Tokens verwenden. Dies hilft bei der Handhabung unterschiedlich komplexer und mehrsprachiger Texte.
- Die Anzahl der Input- und Output-Tokens innerhalb eines Modells sind entscheidend für die Verarbeitungslast und die Kosten der Anfrage, besonders wenn Modelle kommerziell mit Token-Limits abgerechnet werden.
Zusammengefasst sind Input Tokens das Rohmaterial, das einem Modell gegeben wird, um Informationen zu verarbeiten, während Output Tokens das Endprodukt der Verarbeitung sind, das Antworten oder generierten Text darstellt.
Perplexity
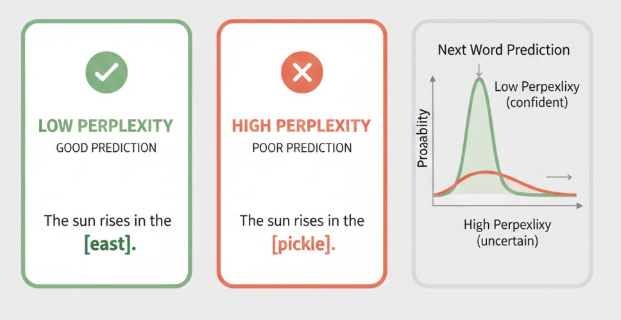
Perplexity ist ein Maß dafür, wie gut ein Sprachmodell (z. B. ChatGPT) das nächste Wort oder Token in einem Satz vorhersagen kann. Es zeigt, wie „unsicher“ oder „verwirrt“ das Modell ist.
- Niedrige Perplexity → Das Modell ist sich sicher, was als Nächstes kommt
- Hohe Perplexity → Das Modell schwankt zwischen vielen Möglichkeiten
Beispiel
Prompt: „Ich trinke morgens gerne …“
Wenn das Modell mit hoher Wahrscheinlichkeit „Kaffee“ vorhersagt, ist die Perplexity niedrig. Wenn es zwischen „Kaffee“, „Tee“, „Wasser“, „Saft“ schwankt, ist die Perplexity höher.
Technischer Hintergrund
- Perplexity basiert auf der Wahrscheinlichkeit einzelner Token
- Sie ist eng verwandt mit der Entropie (Informationsunsicherheit)
- Wird verwendet, um die Qualität eines Sprachmodells zu bewerten
- Je niedriger die Perplexity, desto besser passt das Modell zur Sprache
Wichtig: Perplexity ≠ Wahrheit
Ein Modell kann eine niedrige Perplexity haben – und trotzdem halluzinieren, also falsche Informationen ausgeben. → Perplexity misst sprachliche Sicherheit, nicht inhaltliche Richtigkeit
Completion

Completions sind die Antworten, die ein KI-Modell wie ChatGPT oder Claude (Anthropic) auf einen Prompt gibt. Das Wort „Completion“ bedeutet „Vervollständigung“ – die KI ergänzt den Text logisch und sinnvoll.
Du gibst der KI einen Textanfang – und sie vervollständigt ihn mit einer passenden Antwort.
Die Antwort entsteht durch die Auswahl passender Vektoren – das sind mathematische Repräsentationen von Wörtern und Bedeutungen. Die KI berechnet, welches Wort als nächstes passt, und baut daraus die Antwort.
Um eine Completion zu erzeugen, müssen beim Anbieter ChatGPT ein Systemprompt und ein Nutzerprompt übergeben werden.
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "Du bist ein hilfreicher Assistent"},
{
"role": "user",
"content": "Programmiere mir ein einfaches Snake-Spiel."
}
]
)
print(completion.choices[0].message)
Um eine Completion zu erzeugen, müssen beim Anbieter Anthropic ein „Human Prompt“ und ein „AI Prompt“ übergeben werden.
import anthropic
from anthropic import HUMAN_PROMPT, AI_PROMPT
anthropic.Anthropic().completions.create(
model="claude-2.1",
max_tokens_to_sample=1024,
prompt=f"{HUMAN_PROMPT} Hello, Claude{AI_PROMPT}",
)Kontext
Beim Erzeugen einer Completion berücksichtigt ein KI-Modell den sogenannten Kontext. Das bedeutet: Die KI schaut nicht nur auf den aktuellen Prompt, sondern auch auf alles, was davor gesagt oder gefragt wurde. Dazu gehören frühere Eingaben, Antworten, Rollenangaben und sogar der Sprachstil. Der Kontext hilft der KI, eine Antwort zu geben, die logisch passt und nicht aus dem Zusammenhang gerissen wirkt. Technisch gesehen wird dieser Kontext in Vektoren umgewandelt.
Vektoren
In Sprachmodellen wie ChatGPT werden Wörter nicht als Text gespeichert, sondern als Vektoren – also Zahlenreihen, die die Bedeutung eines Wortes im Raum darstellen. Diese Vektoren zeigen der KI, welche Begriffe zusammengehören und wie sie zueinander stehen. Je besser der Kontext, desto klarer sind die Vektoren ausgerichtet – und desto passender wird die Completion. Ein Beispiel: Wenn du einfach fragst „Was ist ein Apfel?“, bekommst du eine allgemeine Antwort. Wenn du aber vorher sagst „Ich bin Gärtner und unterrichte Azubis“, erkennt die KI den Zusammenhang und erklärt den Apfel berufsbezogen. Kontext ist also wie ein Gedächtnis für die KI – er sorgt dafür, dass die Antwort nicht nur korrekt, sondern auch sinnvoll und verständlich ist.
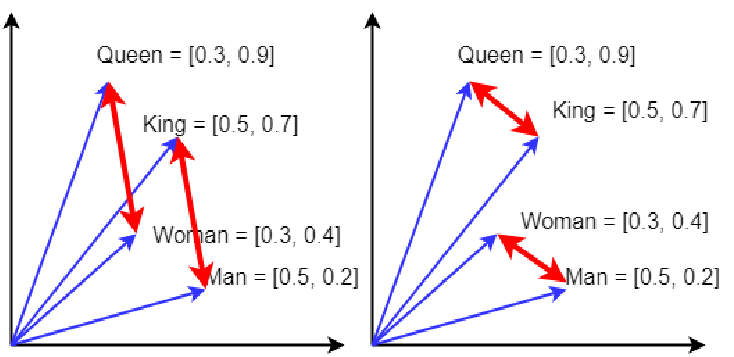
König – Mann + Frau = Königin
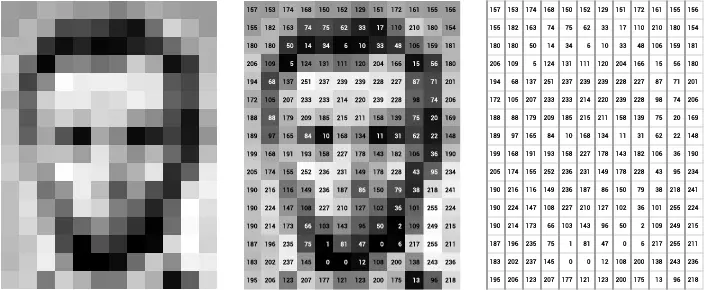
Wie hängen Vektoren mit Kontext zusammen?
Wenn du einen Prompt eingibst, verarbeitet die KI nicht nur das letzte Wort, sondern den gesamten Kontext – also alle vorherigen Wörter, Sätze und sogar Rollen (z. B. „Du bist ein Lehrer“).
- Die KI wandelt diesen Kontext in Vektoren um
- Diese Vektoren helfen der KI zu „verstehen“, worum es geht
- So kann sie eine passende Completion erzeugen
Je besser der Kontext, desto klarer ist die Position der Vektoren – und desto besser wird die Antwort.
Temperatur
Ein Parameter, der die Kreativität oder Zufälligkeit der Ausgabe steuert. Eine höhere Temperatur führt zu diverseren und weniger vorhersagbaren Antworten, während eine niedrigere Temperatur die Ausgaben stabiler und vorhersehbarer macht.
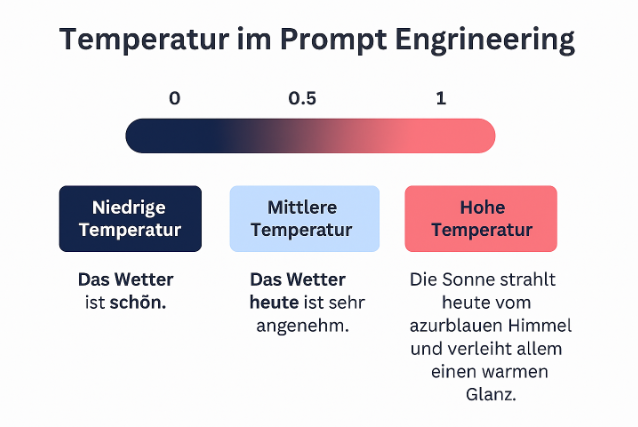
Je höher die Temperatur, umso größer ist auch die Wahscheinlichkeit von Halluzinazionen.
Halluzinantionen
In Bezug auf Large Language Models (LLMs) bezieht sich der Begriff „Halluzinationen“ auf Situationen, in denen das Modell plausibel klingende, aber faktisch falsche oder irreführende Informationen generiert. Diese „Halluzinationen“ entstehen, weil LLMs darauf trainiert sind, sprachlich kohärente Textsequenzen zu erzeugen, und nicht darauf, die inhaltliche Richtigkeit der von ihnen erzeugten Informationen zu gewährleisten.
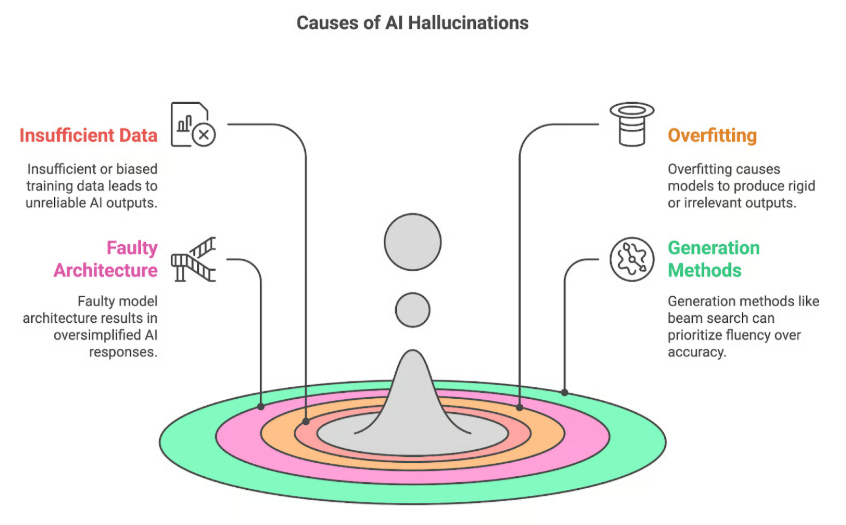
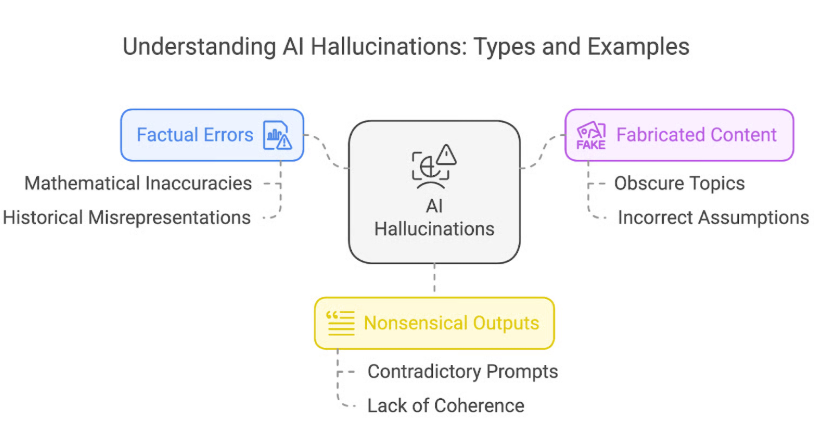
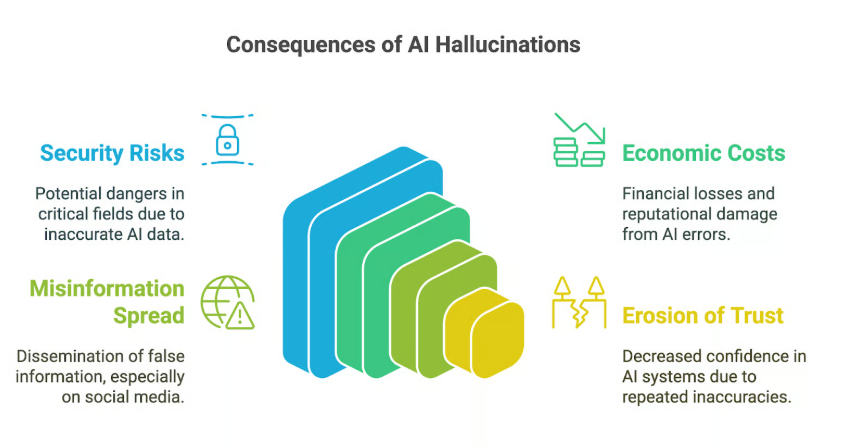
Aufgabe
- Versuchsaufbau zur Erzeugung von Halluzinationen
- Diskutiere in kleinen Gruppen, wie der Prompt verbessert werden kann, um das Ergebnis zu verbessern. Was fehlt z. B. am Ergebnis, um auch Personen ohne Sachkenntnis zu erklären, worüber gerade gesprochen wird?
- Verbessere und erweitere den Prompt, indem spezifischere Angaben gemacht werden, um das Ergebnis zu verbessern
- Ziel
- Das Ziel dieses Experiments ist es, die LLM dazu zu bringen, Informationen zu generieren, die glaubwürdig klingen, aber faktisch ungenau oder erfunden sind.
- Materialien
- Zugang zu einem LLM (z. B. über eine API wie OpenAI GPT-3 oder GPT-4).
- Tools zur Dokumentation der Eingaben und Antworten (z. B. Texteditor, Tabellenkalkulationssoftware).
- Schritte
- Themenwahl:
- Wählen Sie ein Themengebiet aus, auf dem Sie sich etwas auskennen, um die Richtigkeit der Antworten beurteilen zu können (z. B. Geschichte, Wissenschaft, Literatur).
- Erstellen von Prompts:
- Formulieren Sie spezifische Prompts, die wahrscheinlich Halluzinationen verursachen. Diese könnten sehr spezifische oder wenig bekannte Informationen abfragen.
- Beispiel: „Erzähle mir von den Ereignissen des ‚Vergessenen Kriegs‘ im Jahr 1837“ oder „Was war der Haupterlass von Kaiser Maximilian II. über außerirdische Kommunikation?“
- Testdurchführung:
- Geben Sie die Prompts in das LLM ein und dokumentieren Sie die Antworten.
- Wiederholen Sie dies mit mehreren Variationen der Prompts, um unterschiedliche Antworten zu erhalten.
- Analyse der Antworten:
- Bewerten Sie die Antworten auf ihre inhaltliche Richtigkeit. Notieren Sie, welche Aspekte der Antworten halluziniert sind.
- Prüfen Sie, ob es Muster gibt, die häufig zu Halluzinationen führen, z. B. bestimmte Themengebiete oder die Art der Fragestellung.
- Vergleich mit Fakten:
- Vergleichen Sie die generierten Informationen mit verlässlichen Quellen, um die Genauigkeit zu verifizieren.
- Dies kann Bibliotheken, Online-Bibliotheken oder akademische Datenbanken umfassen.
- Berichterstellung:
- Erstellen Sie einen Bericht, der die Versuchsbedingungen, die generierten Antworten und Ihre Analyse der Halluzinationen umfasst. Diskutieren Sie mögliche Gründe, warum das LLM Halluzinationen erzeugt hat.
- Ergebnisse und Reflexion
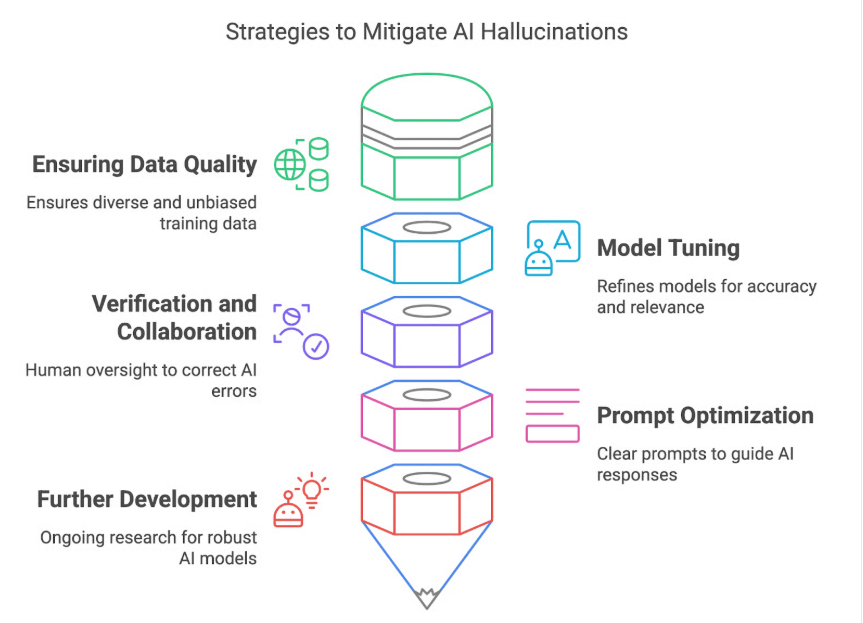
- Analyse der Ursachen solcher Fehler kann helfen, die Grenzen der aktuellen LLMs besser zu verstehen und daran zu arbeiten, sie in zukünftigen Modellen zu verringern. Erkenntnisse über bestimmte Schwachstellen können in der Weiterbildung der Modelle oder bei der Entwicklung von Mechanismen helfen, die solche Fehler erkennen und korrigieren.
- Durch solch ein Experiment können Nutzer auch lernen, kritischer mit den Ausgaben von LLMs umzugehen und sich der Einschränkungen solcher Systeme bewusst zu sein.