4. Unterrichtsblock

Machinelle Lernanwendung zur Bilderkennung
Zielanwendung
- Das Programm soll lernen, Bilder von Hunden und anderen Tieren zu unterscheiden.
- Benötigt wird ein binärer Klassikfikator (Klassifikatoren, die in zwei Gruppen sortieren)
- Perzeptron (Übliches Werkzeug, um so einen Klassifikator zu bauen)
Vortrag aus der letzten Stunde
Effizientere Mengen mit NumPy (Numerisches Python)
Da wir für das Trainieren große Datenmengen benötigen, reichen unsere Dictionarys und Listen nicht aus und wir bedienen uns sog. Arrays und Matritzen aus der Bibliothek NumPy (sonst dauert das Trainieren mehrere Wochen / Monate)
Arrays aus NumPy sind bis zu 50 mal schneller als Listen & Dictionarys aufgrund der optimierten Speicher und Serverarchitekturen der NumPy-Rechner.
- Arrays sind geordnete, änderbare Mengen
- Matritzen (auch Matrix) sind zweidimensionale Arrays, also Arrays von Arrays. In der Mathematik auch als „Tabellen“ bezeichnet.
Der Einbau von NumPy funktioniert über das PIP Modul
Aufgabe
Installiere numpy in VisualStudioCode. Prüfe die erfolgreiche Installation durch Eingabe des folgenden Codes.
import numpy as np
neue_matrix = np.array([[1,2,3],[4,5,6],[7,8,9]])
print(neue_matrix)Erstellen eines Arrays
Um ein Array zu erstellen, verwendet man in numpy das array Schlüsselwort und speichert die Daten in einer Variablen.
groesse = np.array([35.6, 28.4, 55.9, 46.1, 5.2])
print(groesse)Aufgabe
Erstelle ein einzelnes Array für das Schlüssel-Wert-Paar „beine“ aus dem Dicitionary „rohdaten“ heraus
Probiere auch aus, das o.g. Dictionary „rohdaten“ als Ganzes in ein Array zu speichern und prüfe was dabei herauskommt. Diskutiere in der Klassen, ob die Ausgabe so verwendet werden kann. Kleiner Tipp: „Matritze / Matrix“
Erstellen einer Matritze (Matrix)
Um eine Matritze zu erstellen, generieren wir ein Array von einem Array.
import numpy as np
beine = [4, 4, 4, 4, 2]
groesse = [35.6, 28.4, 55.9, 46.1, 5.2]
breite = [32.2, 18.5, 42.8, 39.3, 4.1]
label = [1, 1, 1, 1, 0]
rohdaten = {
'beine': beine,
'groesse': groesse,
'breite': breite,
'label': label
}
# Einzelne Arrays erstellen
groesse = np.array(rohdaten['groesse'])
# Matrix erstellen
feature = np.array([rohdaten['beine'], rohdaten['groesse'], rohdaten['breite']])
print(feature)Aufgabe
Um große Datenmengen zu prüfen, ist es nicht optimal, sich diese komplett durch die print-Funktion ausgeben zu lassen. Recherchiere daher die https://numpy.org/doc/stable/reference/generated/numpy.ndarray.shape.html Funktion, welche die Anzahl der Spalten und Reihen der Matrix anzeigt und probiere diese Funktion aus.
- Recherchiere auch nach der Funktion, welche die Spalten und Reihen vertauscht bzw. transponiert und führe den Tausch durch.
- Recherchiere nach eine NumPy-Funktion, um den Mittelwert von Zahlensammlungen zu errechnen und führe die Funktion bei der ersten Zeile der zuvor transponierten Matrix aus.
Große Datensätze & MatPlotLib
Vortrag aus der letzten Stunde
- Wir benötigen gelabelte Daten
- Die Werten sollen nicht doppelt vorkommen
- Die Werte sollen in einer bestimmten Reihenfolge aufrufbar sein
- Man soll die Werte auch einem bestimmten Schlüssel zuordnen können
- Die Werte müssen Ganzzahlen sein
- Man benötigt eine effiziente Methode, um große Arrays zu verarbeiten
- Wir benötigen eine Matrix (Liste von einer Liste)
- Import von
numpy - Separieren der Eingabedaten und der Labels
Aktueller Projektfortschritt
Um eine Matritze zu erstellen, generieren wir ein Array von einem Array.
import numpy as np
beine = [4, 4, 4, 4, 2]
groesse = [35.6, 28.4, 55.9, 46.1, 5.2]
breite = [32.2, 18.5, 42.8, 39.3, 4.1]
label = [1, 1, 1, 1, 0]
rohdaten = {
'beine': beine,
'groesse': groesse,
'breite': breite,
'label': label
}
# Einzelne Arrays erstellen
groesse = np.array(rohdaten['groesse'])
# Matrix erstellen (Wir erstellen die Matrix vorerst ohne Label,
# da dies in der Praxis oft so ist, dass die Label nachträglich hinzugefügt werden müssen
# Zu Übungszwecken fügen wir die Label auch später nochmal hinzu
feature = np.array([rohdaten['beine'], rohdaten['groesse'], rohdaten['breite']])
print(feature)
# Lösung vorletzte Aufgabe (Shape-Funktion)
print(feature.shape)
# Lösung letzte Aufgabe (transponieren)
print(feature.T)
# Lösung Hausaufgabe
print(np.mean(feature.T, axis=0))Große Datensätze & Erstellen von Label
# Um das Programm zu trainieren werden große Datenmengen benötigt.
import numpy as np
feature = np.array([[4.0, 37.92655435, 23.90101111], # Hund
[4.0, 35.88942857, 22.73639281], # Hund
[4.0, 29.49674574, 21.42168559], # Hund
[4.0, 32.48016326, 21.7340484 ], # Hund
[4.0, 38.00676226, 24.37202837], # Hund
[4.0, 30.73073988, 22.69832608], # Hund
[4.0, 35.93672343, 21.07445241], # Hund
[4.0, 38.65212459, 20.57099727], # Hund
[4.0, 35.52041768, 21.74519457], # Hund
[4.0, 37.69535497, 20.33073640], # Hund
[4.0, 33.00699292, 22.57063861], # Hund
[4.0, 33.73140934, 23.81730782], # Hund
[4.0, 43.85053380, 20.05153803], # Hund
[4.0, 32.95555986, 24.12153986], # Hund
[4.0, 36.38192916, 19.20280266], # Hund
[4.0, 36.54270168, 20.45388966], # Hund
[4.0, 33.08246118, 22.20524015], # Hund
[4.0, 31.76866280, 21.01201139], # Hund
[4.0, 42.24260825, 20.44394610], # Hund
[4.0, 29.04450264, 22.46633771], # Hund
[4.0, 30.04284328, 21.54561621], # Hund
[4.0, 18.95626707, 19.66737753], # Kein Hund
[4.0, 18.60176718, 17.74023009], # Kein Hund
[4.0, 12.85314993, 18.42746953], # Kein Hund
[4.0, 28.62450072, 17.94781944], # Kein Hund
[4.0, 21.00655655, 19.33438286], # Kein Hund
[4.0, 17.33580556, 18.81696459], # Kein Hund
[4.0, 31.17129195, 17.23625014], # Kein Hund
[4.0, 19.36176482, 20.67772798], # Kein Hund
[4.0, 27.26581705, 16.71312863], # Kein Hund
[4.0, 21.19107828, 19.00673617], # Kein Hund
[4.0, 19.08131597, 15.24401994], # Kein Hund
[4.0, 26.69761925, 17.05937466], # Kein Hund
[2.0, 4.44136559 , 3.52432493 ], # Kein Hund
[2.0, 10.26395607, 1.07729281 ], # Kein Hund
[2.0, 7.39058439 , 3.44234423 ], # Kein Hund
[2.0, 4.23565118 , 4.28840232 ], # Kein Hund
[2.0, 3.87875761 , 5.12407692 ], # Kein Hund
[2.0, 15.12959925, 6.26045879 ], # Kein Hund
[0.0, 5.93041263 , 1.70841905 ], # Kein Hund
[0.0, 4.25054779 , 5.01371294 ], # Kein Hund
[0.0, 2.15139117 , 4.16668657 ], # Kein Hund
[0.0, 2.38283228 , 3.83347914 ]]) # Kein Hund
print(feature.shape)
# Erstellen der Label mit der NumPy "Verketten-Funktion" und den NumPy Funktionen "ones" und "zeros"
label = np.concatenate((np.ones(21), np.zeros(22)))
# Indizes auslesen
print(feature[2]) # Ganze Zeile Nr. 3
Aufgabe
- Gib den ersten Wert der zweiten Zeile aus
- Gib alle Werte der ersten Spalte aus und verwende max. 15 Zeichen Code (zzgl.
print()) - Erstelle den Mittelwert aller Werte der ersten Spalte mit der neu erlernten Methode aus NumPy inkl. Achssteuerung
- Gib die vorletzte Zeile der Matrix aus
- Gib den Bereich der Zeilen von 15 – 25 mit einem Befehl aus
- Gib jede dritte Zeile der Matrix aus
Aufgabe (wichtig für den nächsten Schritt)
- Füge die Feature-Matrix und die Label zusammen, sodass jedes Feature ein Label erhält
- Speichere mittels Indizierung die Daten der Fische in eine neue Matrix „fische“
Visualisierung von Daten
In Python visualisert man Daten mit der Bibliothek Matplotlib
Installation
pip install matplotlib
Import
import matplotlibPyplot
Die meisten Matplotlib Anwendungen liegen im pyplot Unterverzeichnis und werden im Normalfall mit dem plt Alias imporitert.
import matplotlib.pyplot as plt
import numpy as np
xPunkte = np.array([0, 6])
yPunkte = np.array([0, 250])
plt.plot(xPunkte, yPunkte) # Anweisung zum Plotten
plt.show() # Anweisung zum Zeigen- Füge die Feature-Matrix und die Label zusammen, sodass jedes Feature ein Label erhält
- Speichere mittels Indizierung die Daten der Fische in eine neue Matrix „fische“
Vortrag aus der letzten Stunde
- Wir benötigen gelabelte Daten
- Die Werten sollen nicht doppelt vorkommen
- Die Werte sollen in einer bestimmten Reihenfolge aufrufbar sein
- Man soll die Werte auch einem bestimmten Schlüssel zuordnen können
- Die Werte müssen Ganzzahlen sein
- Man benötigt eine effiziente Methode, um große Arrays zu verarbeiten
- Wir benötigen eine Matrix (Liste von einer Liste)
- Import von
numpy - Separieren der Eingabedaten und der Labels
- Import von matplotlib und pyplot
- Ausgabe erster Daten als Plot
Visualisierung der Features
Anwendungen von MatplotLib:
Linien plotten: plt.plot()
Balkendiagramme erstellen: plt.bar()
Tortendiagramme erstellen: plt.pie()
Plots anzeigen lassen: plt.show()
Aufgabe
Übe die Anwendungen von matplotlib mit folgenden Tutorial: https://matplotlib.org/stable/tutorials/pyplot.html#sphx-glr-tutorials-pyplot-py
Weitere Tutorials: https://matplotlib.org/tutorials/
Für unsere Anwendung benötigen wir einen sog. „Scatter Plot“. Das sind Plots, die Datenpunkte im Raum visualisieren.
Dies geht mit der Anweisung: plt.scatter()
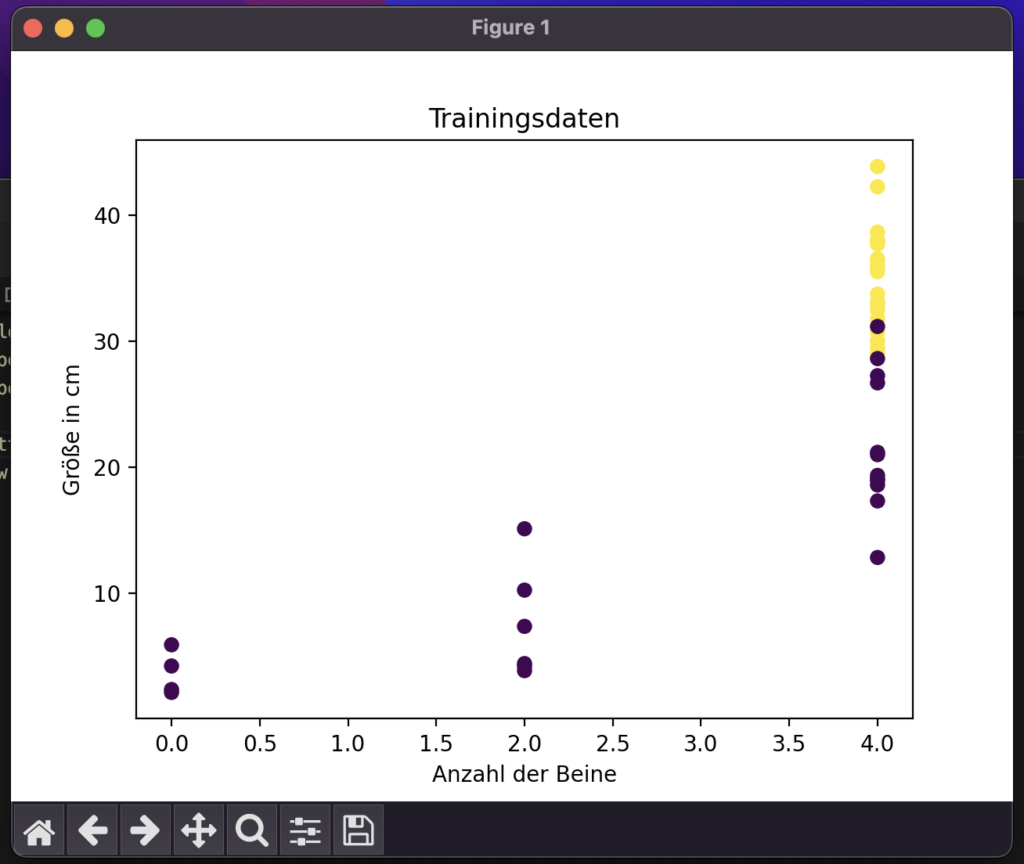
import matplotlib.pyplot as plt
# Versuch Nr. 1.
# Anzahl der Beine auf der X-Achse und Größe auf der Y-Achse
plt.scatter(feature[:,0], feature[:,1])
plt.show()
# Versuch Nr. 2.
plt.title('Trainingsdaten') # Benennung des Plotts
plt.xlabel('Anzahl der Beine') # Benennung der X-Achse
plt.ylabel('Größe in cm') # Benennung der X-Achse
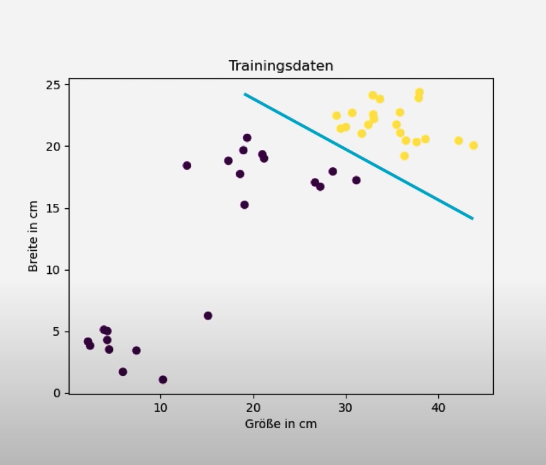
plt.scatter(feature[:,0], feature[:,1], c=label) # Mit dem befehl c=label geben wir jedem Punkt eine extra FarbeNach dem o.g. 2. Versuch werden die Hunde schon klar herausgestellt. Mit den Beschriftungen sieht es auch schon richtig professionell aus.
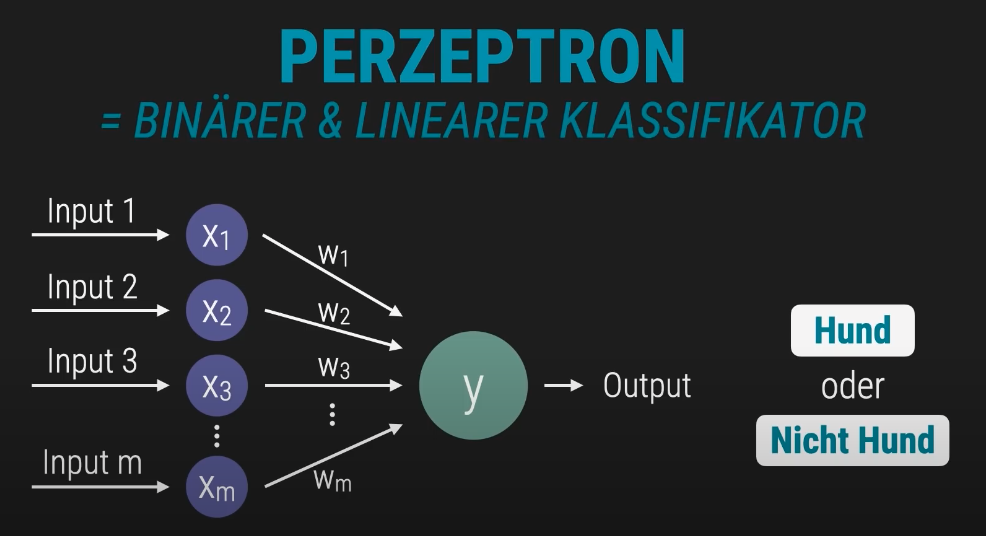
- Das Perzteptron ist neben dem binären Klassifikator auch ein linearer Klassifikator.
- Binärer Klassifikator meint, dass es in der Ausgabe nur zwei Möglichkeiten geben kann
- Linearer Klassifikator meint, dass dieser anhand einer gezogenen Linie klassifizieren / trennen kann (Lineare Separierbarkeit)
Aufgabe
Probiere verschiedene Werte der Features auf der X und Y-Achse aus.
Ziel ist, die Datenpunkte so zu plotten, dass eine linieare Separierbarkeit erreicht werden kann.
Lösung (Versteckt für abgemeldete Nutzer)
Ein einzelnes Perzeptron kann noch nicht viel, wenn jedoch mehrere Perzeptrons zu einem Neuronalen Nezt zusammengeführt werden, kann daraus eine mächtige KI entstehen.
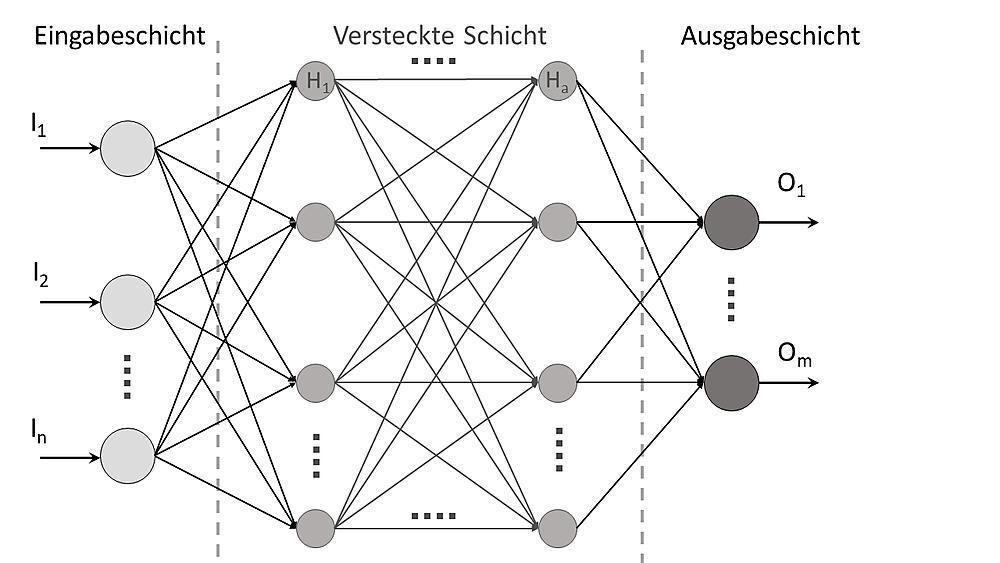
Lineare Separierbarkeit
Aufgabe
Baue den Code so um, dass für die Daten der Hunde eine lineare Separierbarkeit erreicht wird.