7. Unterrichtsblock

Kursinhalte
- Klassen und Objekte in Python
- Strukturierung des Perzeptron-Modells
- Perzeptron als Objekt
- Perzeptron anwenden
- Perzeptron mit SKLearn
Klassen und Objekte in Python
Klassen und Objekte sind dir aus dem Python-Unterricht bereits vertraut. In dieser Einheit lernst du, wie sich diese Konzepte nutzen lassen, um den Perzeptron-Code übersichtlich und modular zu gestalten. Durch die objektorientierte Umsetzung entsteht ein eigenständiges, flexibel einsetzbares Modell, das sich gut in komplexe Programme integrieren lässt und die Wiederverwendbarkeit deutlich erhöht.
Was sind Objekte?
Python ist eine objektorientierte Sprache – nahezu alles, was darin verwendet wird (z. B. Zahlen, Zeichenketten, Listen), sind Objekte. Ein Objekt ist eine Kombination aus Daten (Variablen) und Funktionen (Methoden), die auf diese Daten angewendet werden können.
Mehr dazu findest du im Python-Kurs: https://pythonentwicklerkurs.de/1-2-semester/11-unterrichtsblock/
Klassen als Baupläne
Eine Klasse ist ein Bauplan für ein Objekt. Sie definiert, welche Eigenschaften (Variablen) und Fähigkeiten (Methoden) ein Objekt besitzt. In Python wird eine Klasse mit dem Schlüsselwort class definiert, der Name beginnt üblicherweise mit einem Großbuchstaben.
# Definition einer einfachen Klasse namens Perzeptron
class Perzeptron:
trainiert = False # Klassenvariable: Gibt an, ob das Modell trainiert wurde
# Erstellen eines Objekts (Instanz) der Klasse Perzeptron
test = Perzeptron()
# Ausgabe der trainiert-Eigenschaft des Objekts
print(test.trainiert)Die __init__-Funktion (Konstruktor)
Beim Erstellen eines neuen Objekts wird automatisch die __init__-Funktion aufgerufen. Sie dient der Initialisierung der Objektvariablen. Alle Methoden innerhalb einer Klasse erhalten self als ersten Parameter – eine Referenz auf das jeweilige Objekt. Das entspricht dem Konzept this in anderen Programmiersprachen.
# Definition der Klasse Perzeptron
class Perzeptron:
def __init__(self, max_epochs):
self.trainiert = True # Instanzvariable: Modell gilt als trainiert
self.max_epochs = max_epochs # maximale Anzahl an Trainingsdurchläufen
# Zwei Objekte mit unterschiedlichen Trainingsparametern
test2 = Perzeptron(100)
test3 = Perzeptron(200)
# Ausgabe der trainiert-Eigenschaft beider Objekte
print(test2.trainiert) # → True
print(test3.trainiert) # → True
Instanz- vs. Klassenvariablen
- Instanzvariablen werden mit
self.definiert (z. B.self.gewichte) und sind spezifisch für jedes Objekt. - Klassenvariablen werden ohne
self.direkt in der Klasse definiert und gelten für alle Objekte gleichermaßen – sofern sie nicht überschrieben werden. - Im folgenden werden wir nur Instanzvariablen verwenden:
# Definition der Perzeptron-Klasse mit Initialisierung
class Perzeptron:
def __init__(self, max_epochs):
self.w = None # Gewichtungsvektor (wird später gesetzt)
self.skaliierungsfaktor = None # Skalierungsfaktor für die Normalisierung
self.trainiert = False # Status: Wurde das Modell bereits trainiert?
self.max_epochs = max_epochs # Maximale Anzahl an Trainingsdurchläufen
self.fehler = np.zeros(max_epochs) # Fehlerliste zur Dokumentation pro EpocheHinweis: Diese Struktur legt die Basis für ein objektorientiertes Perzeptron-Modell. Alle relevanten Parameter und Zustände sind als Instanzvariablen definiert, sodass jede Instanz unabhängig trainiert und ausgewertet werden kann. Die Fehlerliste erlaubt später eine Visualisierung des Lernfortschritts über die Epochen hinweg.
Strukturierung des Perzeptron-Modells
Der gesamte Perzeptron-Code wird in eine Klasse integriert. Die __init__-Funktion initialisiert Variablen wie self.gewichte, self.skalierungsfaktor, self.trainiert und self.fehler_historie. Methoden wie perceptron_funktion(), lernschritt(), visualisieren() und plotte_fehler() werden als Funktionen innerhalb der Klasse definiert. Alle internen Verweise auf Variablen und Methoden erfolgen über self. – z. B. self.gewichte. Ein Vorteil: Methoden müssen keine Gewichte mehr als Parameter erhalten, da sie direkt auf die Instanzvariablen zugreifen können.
Perzeptron-Code:
import numpy as np
import matplotlib.pyplot as plt
class Perzeptron():
def __init__(self, max_epochs):
self.w = None
self.skalierungsfaktor = None
self.trainiert = False
self.max_epochs = max_epochs
self.fehler = np.zeros(max_epochs)
def perzeptron(self, x):
if self.trainiert: x /= self.skalierungsfaktor
return 1 if np.dot(self.w, x) > 0 else 0
def lernschritt(self, feature, labels):
# 1. Daten Normalisieren
self.skalierungsfaktor = np.max(feature, 0)
feature /= self.skalierungsfaktor
# 2. Training
iter = 0
self.w = np.random.rand(feature.shape[1])
while iter < self.max_epochs:
for x, label in zip(feature, labels):
delta = label - self.perzeptron(x)
if delta != 0: # falsch klassifiziert
self.fehler[iter] += 1
self.w += (delta * x)
if self.fehler[iter] == 0:
self.trainiert = True
self.visualize(feature, labels)
break
iter += 1
else:
print("Es wurde keine Lösung gefunden.")
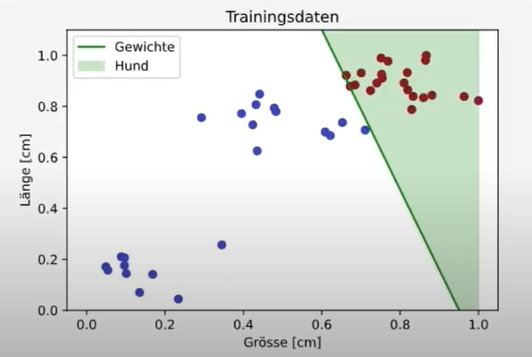
def visualize(self, feature, labels):
_, ax = plt.subplots()
plt.title('Trainingsdaten')
plt.xlabel('Grösse [cm]')
plt.ylabel('Länge [cm]')
plt.scatter(feature[:,0], feature[:,1], c=labels, cmap='coolwarm')
x0 = np.array([0, 1])
w = self.w
if w[1] != 0:
x1 = -(w[0] * x0 + w[2]) / w[1]
plt.plot(x0, x1, color='g', label='Gewichte')
if w[1] > 0:
ax.fill_between(x0, x1, x1+2, alpha=0.2, color='g', label='Hund')
else:
ax.fill_between(x0, x1, x1-1, alpha=0.2, color='g', label='Hund')
ax.set_ylim([0, max(feature[:,1])*1.1])
plt.legend()
plt.show()
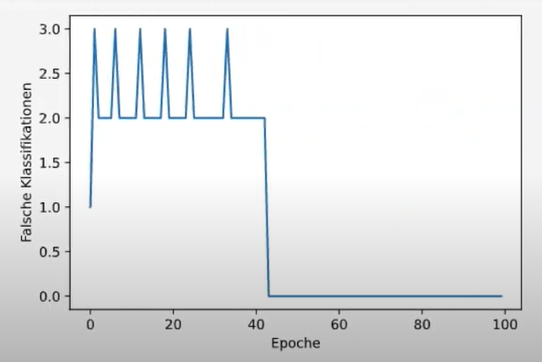
def falsche_klassifikationen(self):
plt.plot(range(self.max_epochs), self.fehler)
plt.xlabel('Epoche')
plt.ylabel('Falsche Klassifikationen')
plt.show()Perzeptron als Objekt
Ein Objekt der Klasse wird erstellt, z. B. perceptron = Perzeptron(100) – mit 100 als maximaler Epochenzahl. Der Lernschritt wird über perceptron.lernschritt(features, labels) ausgeführt. Neue Daten können anschließend mit perceptron.perceptron_funktion(x_neu) klassifiziert werden. Das Modell übernimmt dabei automatisch die Normalisierung, sofern es zuvor trainiert wurde.
class Perzeptron:
...
# Instanziierung und Anwendung der Perzeptron-Klasse
perzeptron = Perzeptron(100) # Neues Perzeptron-Objekt mit 100 Trainingsdurchläufen
# Durchführung eines Lernschritts mit Trainingsdaten
perzeptron.lernschritt(feature, labels) # Methode zum Lernen anhand der Daten
# Ausgabe der Anzahl falscher Klassifikationen
perzeptron.falsche_klassifikationen() # Methode zur Auswertung der Fehler
Jetzt sollte der Plot so aussehen:
Plot Anzahl der falschen Klassifikationen:
Perzeptron anwenden
Um das Perzeptron in der Praxis anwenden zu können, müssen wir den Code noch anpassen. Sodass wir die Klassifikation mit neuen Daten machen können. Neue Eingabedaten sehen zum Beispiel so aus: x_neu = [24.5, 13.8, 1] – also unskalierte Werte plus Bias. Damit das Modell korrekt arbeitet, muss zwischen skalierten Trainingsdaten und unskalierten Anwendungsdaten unterschieden werden. Dafür gibt es die Variable self.trainiert, die nach dem Lernschritt auf True gesetzt wird.
In der Perzeptron-Funktion prüfen wir mit if self.trainiert, ob das Modell trainiert wurde. Falls ja, skalieren wir die Eingabe: x /= self.skalierungsfaktor. So teilen wir durch die gleichen Werte wie beim Training.
Kleiner Trick: Einzeilige Bedingungen lassen sich direkt schreiben, z. B. return 1 if np.dot(self.w, x) > 0 else 0 Das spart Platz und macht den Code lesbarer. Statt return kann man auch eine Variable setzen – Python ist da ziemlich flexibel.
Zur Anwendung: Neue Daten holen, z. B. x_neu, und dann einfach perceptron.perzeptron(x_neu) ausführen. Das Modell klassifiziert automatisch – in unserem Beispiel ist das Tier mit 24,5 cm Länge und 13,8 cm Breite kein Hund.
# Definition der Perzeptron-Klasse mit Klassifikationsmethode
class Perzeptron:
def __init__(self, max_epochs):
# Initialisierung (Details fehlen im Bild)
...
def perzeptron(self, x):
# Klassifikationslogik (Details fehlen im Bild)
...
# Beispielhafte Eingabedaten (z. B. Merkmale eines Tiers)
x_neu = [24.5, 13.8, 1] # z. B. Größe, Gewicht, Bias-Term
# Klassifikation: Ist das ein Hund?
if perzeptron.perzeptron(x_neu):
print("Das ist ein Hund!")
else:
print("Das ist kein Hund…")Das Perzeptron mit SKLearn
Die Scikit-learn (sklearn)-Bibliothek ist ein unverzichtbares Werkzeug im Bereich des Machine Learnings. Sie bietet eine Vielzahl an vorprogrammierten Algorithmen, die das Training von Modellen deutlich vereinfachen und beschleunigen. Die Verwendung einer solchen Bibliothek hat sowohl Vor- als auch Nachteile im Vergleich zur eigenen Programmierung.
Vergleich: Eigener Code vs. Sklearn
| Kriterium | Eigener Code | Scikit-learn |
|---|---|---|
| Vorteile | – Verständnis: Man lernt die Funktionsweise des Algorithmus von Grund auf kennen. <br> – Transparenz: Jeder Schritt ist nachvollziehbar und kann visualisiert werden. <br> – Flexibilität: Man kann jeden Aspekt des Algorithmus anpassen. | – Geschwindigkeit: Die Algorithmen sind hochgradig optimiert und laufen deutlich schneller (z. B. 16-mal schneller als eine eigene Perceptron-Implementierung). <br> – Stabilität: Bietet robuste und fehlerbereinigte Implementierungen. <br> – Einfachheit: Ermöglicht die schnelle und einfache Anwendung von Algorithmen in wenigen Zeilen Code. |
| Nachteile | – Laufzeit: Die Ausführung ist langsamer. <br> – Komplexität: Mehr Codeaufwand für dieselbe Aufgabe. | – Abstraktion: Man sieht die interne Funktionsweise des Algorithmus nicht, was das Verständnis erschwert. <br> – Geringere Flexibilität: Die Anpassung ist auf die von der Bibliothek vorgesehenen Parameter beschränkt. |
Perceptron mit Sklearn
Mit Scikit-learn ist die Implementierung eines Perceptrons denkbar einfach. Anstatt den Algorithmus von Grund auf zu programmieren, wird die Perceptron-Klasse aus sklearn.linear_model importiert. Das Training des Modells erfolgt dann über die .fit()-Methode.
# Import der Perzeptron-Klasse aus scikit-learn
from sklearn.linear_model import Perceptron
# Erstellen eines Perzeptron-Modells mit Standardparametern
sk_perzeptron = Perceptron()
# Training des Modells mit Eingabedaten (feature) und Zielwerten (label)
sk_perzeptron.fit(feature, label)
Einblick in Support Vector Machines (SVM)
Über das Perceptron hinaus bietet Scikit-learn auch komplexere und leistungsfähigere Algorithmen, wie die Support Vector Machines (SVMs). SVMs sind eine Erweiterung des Perceptrons. Während ein Perceptron eine beliebige Trennlinie findet, optimiert eine SVM diese Linie, um den größtmöglichen Abstand zu den am nächsten liegenden Datenpunkten zu gewährleisten.
Dank sogenannter Kernels können SVMs auch mit nicht-linear trennbaren Daten umgehen und komplexere, nicht-gerade Trennlinien finden. Auch hier ist die Implementierung mit Scikit-learn einfach und effizient.
# Import eines Support Vector Classifiers (SVC) aus scikit-learn
from sklearn.svm import SVC
# Erstellen eines SVM-Modells mit Standardparametern
svm = SVC()
# Training des Modells mit Eingabedaten (feature) und Zielwerten (label)
svm.fit(feature, label)
# Visualisierung des trainierten Modells (plot_svm muss separat definiert sein)
plot_svm(svm, feature, label)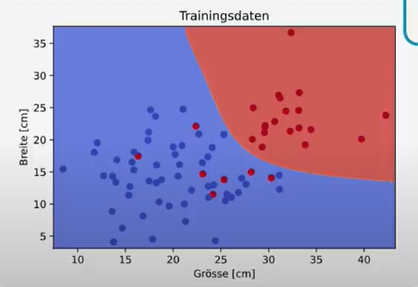
Praktische Übungen und Vertiefung
Um das erlernte Wissen nicht zu Vergessen, kann es an weiteren Machine Learning Beispielen ausprobieren.
- Algorithmus-Rekonstruktion z.B. Nachprogrammieren klassischer ML-Algorithmen (z. B. SVM) zur Vertiefung des Verständnisses
- Neuronale Netze mit PyTorch oder TensorFlow
- Modellaufbau mit Keras
Video:
#20: https://www.youtube.com/watch?v=8LosC2Fszis&list=PLIYzsTnFhywyjBon1_tE4ZGVzXAx5FpWr&index=20 #21: https://www.youtube.com/watch?v=Vjugt6Fx0kY&list=PLIYzsTnFhywyjBon1_tE4ZGVzXAx5FpWr&index=21