3. Unterrichtsblock

Kursinhalte
Machinelle Lernanwendung zur Bilderkennung
In dieser Unterrichtsreihe werden wir uns dem Thema Machine Learning nähern. Basierend auf euren bisherigen Kenntnissen in Python und der Nutzung der Entwicklungsumgebung, beginnen wir mit der praktischen Implementierung eines lernenden Systems.
Wir konzentrieren uns auf das Perzeptron, ein grundlegendes Modell aus dem Bereich der Neuronalen Netze. Ziel ist es, eine eigene Machine Learning-Anwendung zu entwickeln, die in der Lage ist, aus gegebenen Daten zu lernen und einfache Klassifizierungsaufgaben durchzuführen.
Die Inhalte umfassen:
- Die grundlegende Struktur und Funktionsweise eines Perzeptrons.
- Die Implementierung des Lernalgorithmus in Python.
- Das Training des Modells mit Beispieldaten.
Diese Reihe dient dazu, das Prinzip des maschinellen Lernens durch eine praktische Umsetzung besser zu verstehen.
Ziel der Anwendung
- Hauptaufgabe des Programms:
- Das Programm soll lernen, Bilder zu erkennen und diese zu kategorisieren.
- Es soll Bilder von Hunden von Bildern anderer Tiere unterscheiden.

- Der benötigte Werkzeugtyp:
- Dafür brauchen wir einen sogenannten binären Klassifikator.
- Klassifikator: Ein Programm, das Daten (in unserem Fall Bilder) in verschiedene vordefinierte Kategorien („Klassen“) einteilt.
- Binär: Bedeutet, dass es nur zwei mögliche Ausgaben oder Gruppen gibt. Unser Klassifikator wird ein Bild entweder der Kategorie „Hund“ oder der Kategorie „Nicht-Hund“ (d.h. „anderes Tier“) zuordnen.
- Unser Werkzeug der Wahl:
- Um diesen binären Klassifikator zu bauen, werden wir ein Perzeptron verwenden.
- Das Perzeptron ist ein grundlegendes Modell eines Neuronalen Netzes und ein übliches Werkzeug, um solche Klassifikatoren zu konstruieren, die einfache Muster erkennen und lernen können.
Vokabeln
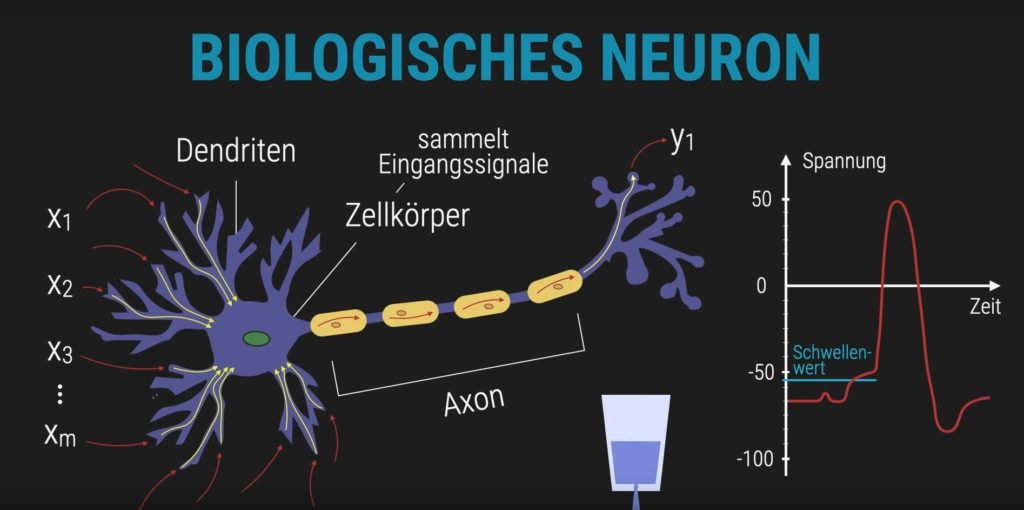
Neuron
Ein biologisches Neuron ist eine spezialisierte Nervenzelle, die Informationen verarbeitet und weiterleitet. Es empfängt elektrische Signale über seine Verästelungen, die sogenannten Dendriten. Diese Signale werden im Zellkörper gesammelt und miteinander verrechnet. Wenn die Summe der eingehenden Signale einen bestimmten Schwellenwert überschreitet, erzeugt das Neuron ein Ausgangssignal – es „feuert“. Dieses Signal wird über das Axon weitergeleitet und kann andere Neuronen aktivieren. Auf diese Weise entstehen komplexe Informationsflüsse im Nervensystem, die z. B. Bewegungen, Wahrnehmung oder Entscheidungen steuern.
Was ist ein Perzeptron?
Ein Perzeptron ist ein einfaches Modell eines künstlichen Neurons und gilt als Grundbaustein für viele moderne KI-Systeme. Es basiert auf der mathematischen Nachbildung biologischer Nervenzellen, insbesondere auf dem sogenannten McCulloch-Pitts-Neuron, das bereits 1943 entwickelt wurde.
Dieses ursprüngliche Modell stellte ein Neuron als logisches Schwellwert-Element dar: Es empfängt mehrere Eingangssignale, summiert sie und gibt nur dann eine 1 aus –, wenn die Summe einen bestimmten Schwellenwert überschreitet. Andernfalls bleibt die Ausgabe 0.
Frank Rosenblatt entwickelte dieses Konzept weiter und schuf daraus das Perzeptron: Ein lernfähiges System, das Eingaben gewichtet, entscheidet, ob sie eine bestimmte Bedingung erfüllen, und durch Anpassung der Gewichtungen aus Fehlern lernen kann. Damit wurde das Perzeptron zum ersten praktischen Modell für maschinelles Lernen und zur Grundlage für spätere neuronale Netzwerke.
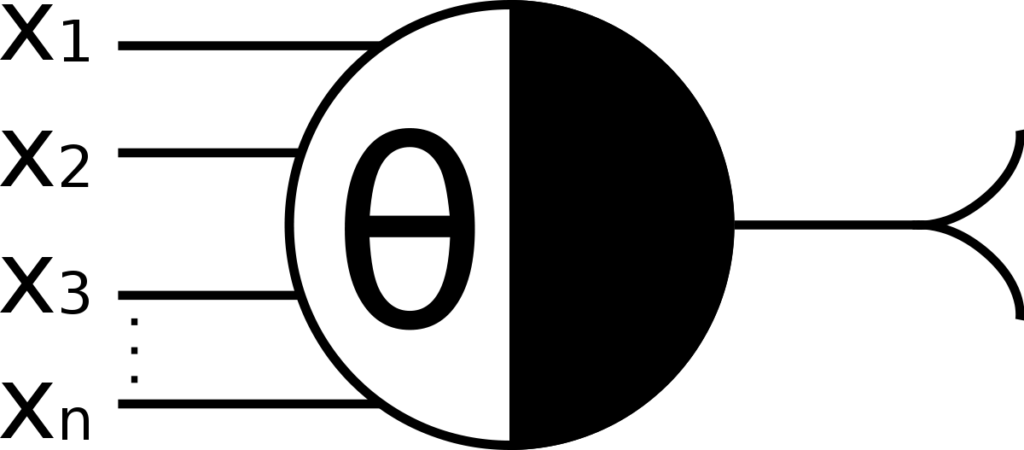
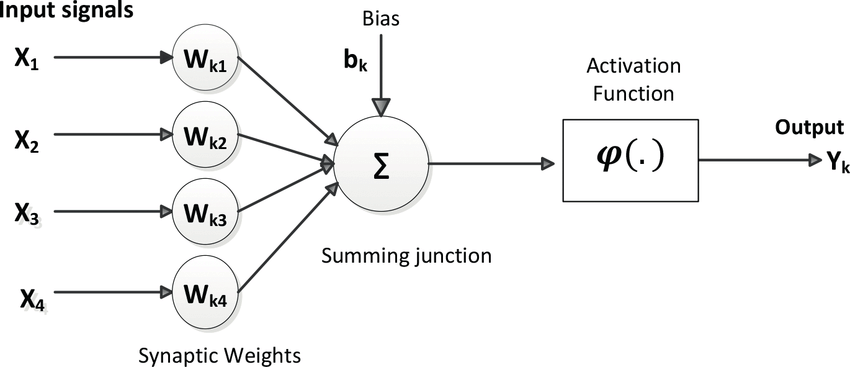
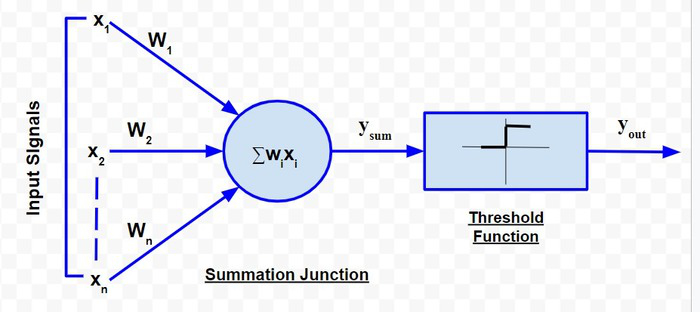
Verschiedene mathematische Nachbildungen des McCulloch-Pitts-Neurons
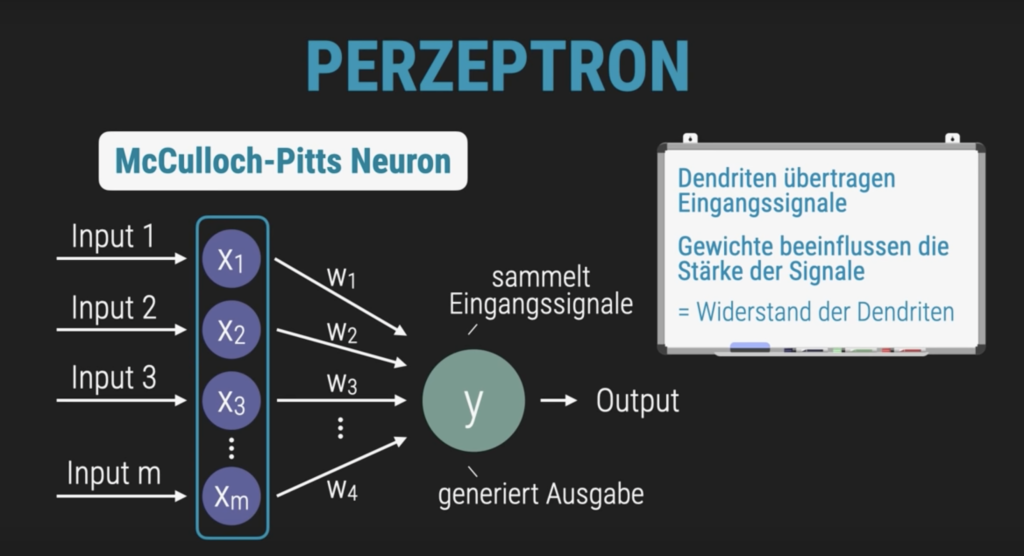
Eingangssignale
Im Rahmen unseres Projekts zur Bilderkennung sind die ursprünglichen Eingangssignale für unser lernendes System tatsächlich die Bilder von Hunden und anderen Tieren selbst.
Da Python-Code jedoch nicht direkt mit rohen Bilddateien in ihrer visuellen Form (wie wir sie mit den Augen sehen) rechnen kann, müssen wir diese visuellen Informationen zuerst in eine numerische Form umwandeln. Dieser Prozess wird als Feature-Extraktion oder Datenrepräsentation bezeichnet.
Anstatt das komplette Bild zu verarbeiten, werden wir für unser einfaches Perzeptron aus jedem Bild bestimmte, ausgewählte Eigenschaften – sogenannte Merkmale (Features) – ableiten. Dies können beispielsweise sein:
- Die Anzahl der Beine des abgebildeten Tiers.
- Die durchschnittliche Größe oder Breite des Tiers im Bild.
- Die dominanteste Farbe des Fells oder Gefieders.
Diese Merkmale werden dann als numerische Werte (wie 4 Beine, 35.6 cm Größe, oder eine Farbkodierung) oder in eine numerische Form überführte Kategorien (wie 1 für Hund, 0 für Nicht-Hund) in das Perzeptron eingespeist. Die Umwandlung von komplexen visuellen Daten in eine strukturierte Menge von Zahlen ist ein entscheidender erster Schritt, um Machine Learning-Algorithmen überhaupt erst anwenden zu können.
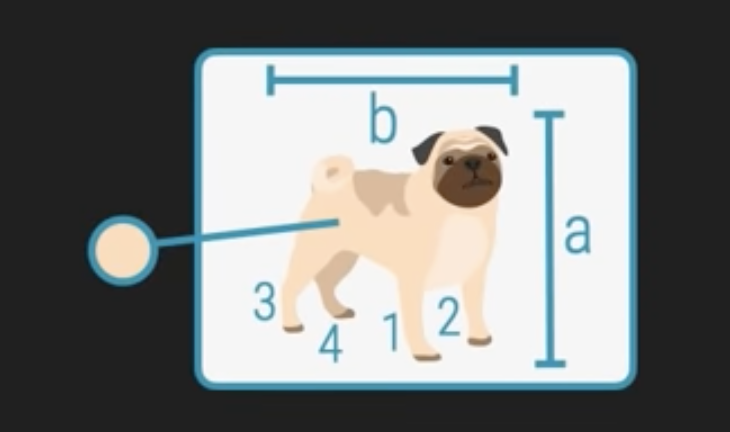
Die Variablen (sog. „Feature“ z. B. Größe, Farbe, Anzahl der Beine) werden als Eingangssignale x1, x2, … xm in das Perzeptron gegeben.
beine = 4
groesse = 35.6
breite = 34.2
farbe = 'Beige'
label = 'Hund'Binärer Klassifikator
Ein binärer Klassifikator ist ein fundamentaler Baustein im Machine Learning, der immer dann zum Einsatz kommt, wenn eine Entscheidung zwischen genau zwei möglichen Optionen getroffen werden muss. Sein primärer Zweck ist es, Daten zu kategorisieren und zu sortieren, indem er eine „Ja/Nein“- oder „A/B“-Antwort auf eine gegebene Frage liefert. Dies ermöglicht es uns, Informationen zu filtern, spezifische Eigenschaften in Datensätzen zu erkennen oder Elemente voneinander zu separieren.
Beispiel: Ist das ein Hund oder kein Hund? Das Ergebnis ist immer entweder Klasse A oder Klasse B – also „Ja“ oder „Nein“, „1“ oder „0“.
Unterschied: Binärer Klassifikator vs. Perzeptron
| Merkmal | Binärer Klassifikator | Perzeptron |
|---|---|---|
| Funktion | Trifft Entscheidung zwischen zwei Klassen | Trifft Entscheidung zwischen zwei Klassen |
| Typ | Allgemeiner Begriff | Spezielles Modell eines binären Klassifikators |
| Lernmethode | Kann verschiedene Algorithmen nutzen | Nutzt gewichtete Eingaben + Schwellenwert |
| Beispiele | Entscheidungsbaum, SVM, logistische Regression | Einfaches neuronales Netz mit 1 Neuron |
| Einschränkungen | Modellabhängig | Funktioniert nur bei linear trennbaren Daten |
Aufgabe
Begriffsverständnis: Erkläre, was ein Klassifikator ist. → Was macht ein Klassifikator? → Welche Art von Daten verarbeitet er?
Kategorisierung: Ordne den Klassifikator einer der drei Hauptkategorien des maschinellen Lernens zu:
- Überwachtes Lernen
- Unüberwachtes Lernen
- Bestärkendes Lernen Begründe deine Entscheidung.
Beispielanalyse: Nenne ein konkretes Beispiel für einen Klassifikator aus dem Alltag (z. B. Spam-Erkennung, Bilderkennung, Diagnosesystem). → Welche Eingabedaten werden verwendet? → Welche Klassen werden unterschieden?
Reflexion: Warum ist es wichtig, dass ein Klassifikator mit gelabelten Daten trainiert wird? Was passiert, wenn die Trainingsdaten fehlerhaft oder unvollständig sind?
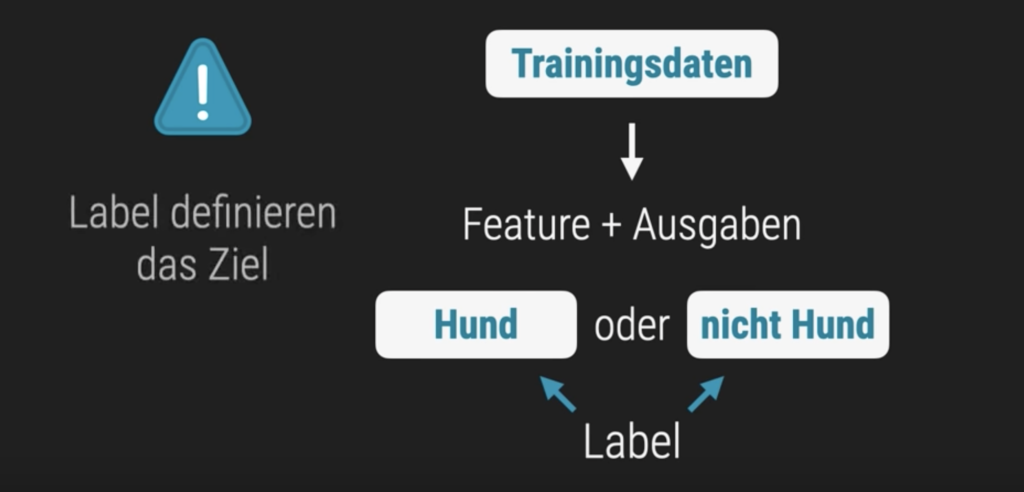
Mit Mengen arbeiten & Trainingsdaten
Zunächst werden Beispieldaten benötigt, die bereits gelabelt sind.
In Python gibt es mehrere Datentypen zum speichern von Mengen:
- Set ist eine Sammlung, die ungeordnet, unveränderlich* und nicht indiziert ist. Keine doppelten Werte.
- Tuple ist eine Sammlung, die geordnet und unveränderlich ist. Erlaubt doppelte Werte.
- Liste ist eine Sammlung, die geordnet und veränderbar ist. Erlaubt doppelte Werte.
- Dictionary ist eine Sammlung, die geordnet** und veränderbar ist. Keine doppelten Schlüssel.
*Set- Elemente können nicht geändert werden, aber man kann Elemente jederzeit entfernen und/oder hinzufügen.
**Ab Python-Version 3.7 sind Dictionaries geordnet. In Python 3.6 und früher sind Dictionaries ungeordnet.
# Menge als Set
feature = {4, 35.6, 34.2, "Beige", "Hund"}
# Menge als Tupel
feature = (4, 35.6, 34.2, "Beige", "Hund")
# Menge als Liste
feature = [4, 35.6, 34.2, "Beige", "Hund"]
# Menge als Dictionary
feature = {
'beine': 4,
'groesse': 35.6,
'breite': 32.2,
'farbe': "Braun",
'label': "Hund"
}Aufgabe
- Gib jeweils einen Wert aus:
– dem Set
– dem Tuple
– der Liste
– dem Dictionary - Beantworte folgende Fragen schriftlich:
– Was unterscheidet die vier Strukturen? → Reihenfolge, Zugriff, Veränderbarkeit, Duplikate
– Welche Struktur eignet sich am besten für unseren Anwendungsfall? → z. B. wenn wir Merkmale eines Tiers speichern wollen
– Was passiert, wenn du versuchst, einen Wert zu ändern? → Teste das bei Liste, Tuple und Dictionary - Diskutiere in der Klasse, welcher Mengendatentyp für unseren Anwendungsfall am besten geeignet ist. Bedenke, dass der Code schlank bleiben soll.
- Gib einen Sammelwert (z. B. eine Liste oder ein Set) aus der oben genannten Menge aus und anschließend einen Einzelwert daraus. → Beispiel: Zugriff auf eine Liste innerhalb eines Dictionaries und dann auf ein Element darin.
- Erstelle ein Dictionary mit Deinen Lieblingsfilmen / Lieblingsspielen / Lieblingsbüchern und versuche die einzelnen Werte in Listen zu speichern.
Fazit und Ausblick: Warum Dictionaries die Wahl für Tier-Merkmale sind
Wir haben gesehen, dass Python verschiedene Datenstrukturen für unterschiedliche Zwecke bietet. Listen und Tupel sind hervorragend für geordnete Sammlungen, wobei Tupel den zusätzlichen Vorteil der Unveränderlichkeit bieten. Sets glänzen, wenn es um die schnelle Verwaltung einzigartiger Elemente geht.
Doch wenn es darum geht, die Merkmale eines einzelnen Tiers – wie Fellfarbe, Größe und ob es ein Hund ist – logisch und lesbar zu speichern, führt kein Weg am Dictionary vorbei. Seine Fähigkeit, Informationen als Schlüssel-Wert-Paare abzulegen (z.B. "fellfarbe": "braun"), macht den Code intuitiv verständlich und leicht zu handhaben. Dies ist entscheidend, denn im Machine Learning wollen wir unsere Daten nicht nur speichern, sondern auch verstehen und gezielt darauf zugreifen.
Aber was, wenn wir nicht nur die Merkmale eines Tiers speichern wollen, sondern eine ganze Sammlung von Tieren? Oder wenn ein Tier mehrere Werte für ein Merkmal hat, wie zum Beispiel eine Liste von möglichen Farben oder eine Liste von bekannten Tricks? Genau dann werden wir die Stärken von Dictionaries mit der Flexibilität von Listen kombinieren müssen.
Im nächsten Schritt werden wir daher lernen, wie wir Dictionaries noch mächtiger machen, indem wir sie mit Listen verbinden, um komplexere Datenstrukturen abzubilden und so unsere Tier-Merkmale noch präziser für unser lernendes Perzeptron vorzubereiten.
Dictionary mit mehreren Listen
Vortrag aus dem letzten Teil
- Wir benötigen gelabelte Daten
- Die Werten sollen nicht doppelt vorkommen
- Die Werte sollen in einer bestimmten Reihenfolge aufrufbar sein
- Man soll die Werte auch einem bestimmten Schlüssel zuordnen können
Wir haben Dictionaries als flexible Datenregister kennengelernt, die Daten in Schlüssel-Wert-Paaren speichern. Für die Merkmale eines einzelnen Objekts sind sie ideal. Doch im Machine Learning benötigen wir oft eine Möglichkeit, mehrere Objekte und deren verschiedene Merkmale effizient zu verwalten. Das bedeutet, dass wir nicht nur einen einzelnen Wert pro Merkmal speichern, sondern eine Liste von Werten – einen für jedes Objekt in unserem Datensatz.
Hier kommt die leistungsstarke Kombination ins Spiel: Wir verwenden ein Dictionary, bei dem die Schlüssel die Namen der Merkmale (z.B. ‚beine‘, ‚groesse‘, ‚label‘) sind und die Werte jeweils Listen sind, die die entsprechenden Daten für alle unsere Beobachtungen enthalten.
Warum diese Struktur für Machine Learning-Daten?
- Ordnung & Kontext: Jeder Merkmalsname (Schlüssel) bleibt logisch mit einer Liste von Werten verknüpft. Das verbessert die Lesbarkeit erheblich.
- Flexibilität: Die Listen können beliebig viele Werte aufnehmen, je nachdem, wie viele Datenpunkte (z.B. Tierbilder) wir in unserem Datensatz haben.
- Zugriff: Mit dem Schlüssel gelangen wir zur richtigen Merkmalsliste, und mit dem Index innerhalb der Liste können wir auf den Wert eines spezifischen Datenpunkts zugreifen (z.B.
feature['groesse'][2]für die Größe des dritten Tiers). - Gleichlänge der Listen: Für die meisten ML-Anwendungen ist es entscheidend, dass alle Listen innerhalb eines solchen Dictionaries dieselbe Länge haben. Jedes Element an einem bestimmten Index (z.B. Index 0) in den verschiedenen Listen repräsentiert dann die vollständigen Merkmale eines einzigen Datenpunkts.
Numerische und Kategorische Merkmale im feature-Dictionary
Um unser Perzeptron effektiv trainieren zu können, ist es entscheidend, die Art unserer Merkmale zu verstehen:
- Numerische Merkmale sind Werte, die als Zahlen ausgedrückt werden können und eine quantitative Bedeutung haben. Mit ihnen kann man rechnen. In unserem
feature-Dictionary sind dies'beine','groesse'und'breite'. Diese Werte sind direkt für mathematische Operationen geeignet. - Kategorische Merkmale repräsentieren Qualitäten oder Klassifikationen, die keine natürliche numerische Reihenfolge oder Rechenoperationen erlauben. Sie sind oft Textbeschreibungen. In unserem Dictionary sind
'farbe'und'label'kategorische Merkmale. Ein Perzeptron kann mit diesen Textwerten in ihrer ursprünglichen Form nicht direkt arbeiten, da es mathematische Eingaben benötigt.
Diese Unterscheidung ist der erste Schritt zur Datenvorbereitung für unser Machine Learning-Modell.
Beispiel: Unser Feature-Dictionary für Tier-Merkmale
Stellen wir uns vor, wir haben Messdaten von fünf Tieren, wobei jedes Tier eine Reihe von Merkmalen aufweist. Jede Liste stellt dabei die Werte für ein Merkmal über alle fünf Tiere hinweg dar.
# # Listen für jedes Merkmal, die die Daten aller fünf Tiere enthalten als Dictionary mit mehreren Listen
beine = [4, 4, 4, 4, 2] # z.B. Anzahl der Beine für 4 Hunde und 1 Vogel
groesse = [35.6, 28.4, 55.9, 46.1, 5.2] # Größe in cm für jedes Tier
breite = [32.2, 18.5, 42.8, 39.3, 4.1] # Breite in cm für jedes Tier
farbe = ["Braun", "Schwarz", "Beige", "Weiß", "Rot"] # Fell-/Federfarbe für jedes Tier
label = ["Hund", "Hund", "Hund", "Hund", "nicht Hund"] # Die gewünschte Klassifizierung für jedes Tier
# Ein Dictionary, das alle diese Merkmalslisten unter sprechenden Schlüsseln zusammenführt
feature = {
'beine': beine,
'groesse': groesse,
'breite': breite,
'farbe': farbe,
'label': label
}
# Zugriff auf die gesamte Liste eines Merkmals
print(f"Alle Bein-Anzahlen: {feature['beine']}") # Ausgabe: [4, 4, 4, 4, 2]
# Zugriff auf ein spezifisches Merkmal eines bestimmten Tiers (z.B. Größe des 3. Tiers, Index 2)
print(f"Größe des 3. Tiers: {feature['groesse'][2]} cm") # Ausgabe: 55.9 cmIn diesem feature-Dictionary repräsentiert:
- Jeder Schlüssel (z.B.
'beine') ein spezifisches Merkmal (Feature). - Der Wert zu diesem Schlüssel (z.B.
[4, 4, 4, 4, 2]) ist eine Liste, die die Ausprägungen dieses Merkmals für jedes der fünf Tiere enthält. - Der Wert an Index
iin jeder Liste (feature['beine'][i],feature['groesse'][i], etc.) gehört zumi-ten Tier im Datensatz.
Aufgabe
- Gib einen Sammelwert (z. B. eine Liste wie
feature["farbe"]) und einen Einzelwert (z. B.feature["farbe"][2]) aus dem Dictionary aus. - Diskutiere in der Klasse:
- Welche Merkmale im Dictionary sind numerisch, welche kategorisch?
- Warum kann ein Perzeptron nur mit numerischen Werten arbeiten?
- In unser Dictionary haben sich zwei Schlüssel-Wert-Paare eingeschlichen, die so noch nicht verarbeitet werden können. Eines der Schlüssel-Wert-Paare kann für die weitere Verrabeitung konvertiert werden. Das andere für unser einfaches Beispiel nicht. Entscheide:
- Welche Schlüssel-Wert-Paare sind für das Perzeptron nicht direkt verwertbar?
- Wähle eines davon aus, das du aussortierst. Das Entfernen der des Schlüssel-Wertpaares aus dem Dictionary soll progammatisch erfolgen
- Wähle ein anderes, das du umbenennst und umwandelst, sodass es numerisch wird (z. B.
"label": "Hund"→"label": 1) Die Lösung soll programmatisch erfolgen.
- Begründe deine Entscheidungen:
- Warum ist die Umwandlung notwendig?
- Was passiert, wenn man kategorische Daten nicht umwandelt?
Die Grenzen von Dictionaries für Machine Learning
Wir haben Dictionaries als flexible und intuitive Datenstrukturen kennengelernt, die sich hervorragend eignen, um Daten in Form von Schlüssel-Wert-Paaren zu organisieren. Sie bieten eine hohe Lesbarkeit und einen schnellen Zugriff auf einzelne Elemente anhand ihrer beschreibenden Schlüssel. Für kleinere, logisch benannte Datensätze oder die Speicherung von Konfigurationen sind sie eine ausgezeichnete Wahl.
Doch im Bereich des Machine Learnings, wo wir es häufig mit sehr großen, homogenen und numerischen Datensätzen zu tun haben (z.B. Millionen von Pixelwerten, Messreihen oder Modellparametern), stoßen Dictionaries und auch die grundlegenden Python-Listen an ihre Grenzen:
- Ineffizienz bei Speicher und Datentypen:
- Python-Dictionaries (und Listen) sind äußerst flexibel, da sie Elemente unterschiedlicher Datentypen (ganze Zahlen, Fließkommazahlen, Zeichenketten etc.) speichern können. Diese Flexibilität hat jedoch einen Preis: Für jedes einzelne Element müssen zusätzliche Metadaten gespeichert werden, da Python den Typ des nächsten Elements nicht vorhersagen kann.
- Bei Machine Learning-Anwendungen liegen Daten jedoch oft in einer sehr einheitlichen Form vor (z.B. große Mengen an Fließkommazahlen). Die Speicherung all dieser Metadaten für Millionen von Elementen führt zu einem erheblich erhöhten Speicherverbrauch, der bei der Verarbeitung großer Datensätze schnell ineffizient wird.
- Mangelnde Performance bei numerischen Operationen:
- Mathematische Operationen, die über alle Elemente einer Liste oder die Werte eines Dictionaries ausgeführt werden sollen (z.B. das Addieren von zwei Vektoren oder das Multiplizieren einer Matrix), müssen in Standard-Python oft mittels expliziter Schleifen implementiert werden.
- Diese Schleifen sind in Python, das eine interpretierte Sprache ist, vergleichsweise langsam. Für die enormen Mengen an numerischen Berechnungen, die in Machine Learning-Algorithmen anfallen (Matrizenoperationen, Vektoradditionen, elementweise Funktionen), sind diese Operationen nicht ausreichend performant. Die Rechenzeit würde ins Unermessliche steigen.
Diese Einschränkungen zeigen, dass wir für die Anforderungen des Machine Learnings, insbesondere die effiziente Handhabung von großen, numerischen und homogenen Datenmengen, speziellere und leistungsfähigere Datenstrukturen benötigen.
Dies führt uns direkt zur Einführung von NumPy, einer Bibliothek, die genau diese Probleme löst, indem sie optimierte Arrays bereitstellt, die in C implementiert sind und somit sowohl speichereffizient als auch extrem schnell bei numerischen Operationen sind.

Arrays aus NumPy sind bis zu 50 mal schneller als Listen & Dictionarys aufgrund der optimierten Speicher und Serverarchitekturen der NumPy-Rechner.
- Arrays sind geordnete, änderbare Mengen
- Matritzen sind zweidimensionale Arrays, also Arrays von Arrays